Andrej Karpathy:神奇大模型不存在的,只是对人类标注的拙劣模仿
文章摘要
【关 键 词】 AI质疑、数据标注、RLHF批判、模型限制、规则奖励
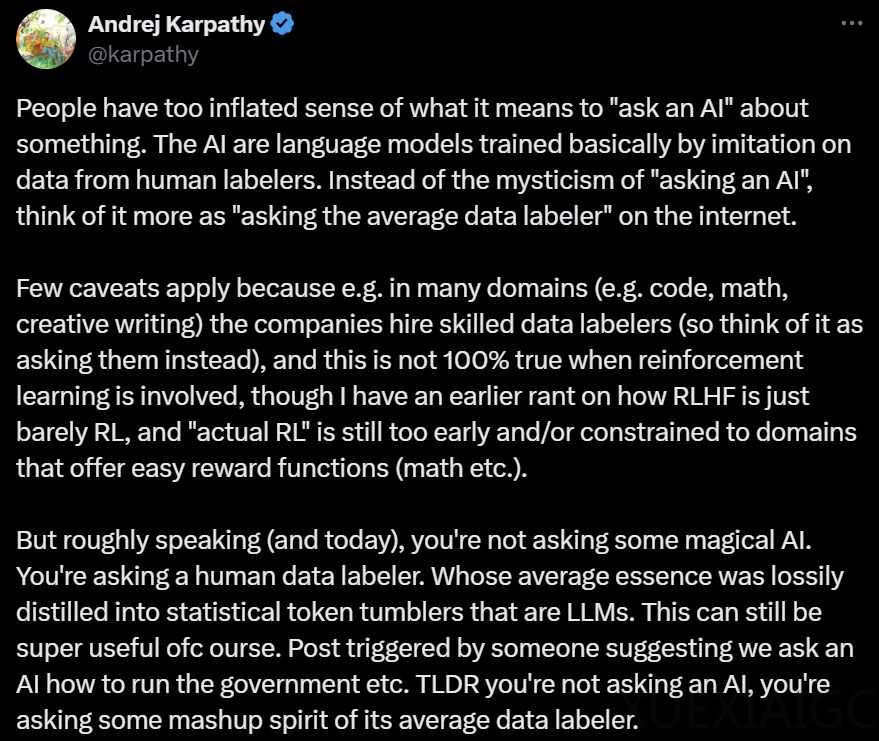
AI领域学者Andrej Karpathy对当前人工智能对话模型的“智能”成分提出了质疑。他认为,人工智能实际上是通过模仿人工标注数据进行训练的语言模型,因此将对话视为“询问人工智能”是一种误解,更应看作是“询问互联网上的平均数据标注者”。Karpathy指出,当问题的答案不在微调训练集中时,神经网络会根据预训练阶段获得的知识进行估计。他进一步解释,RLHF(Reinforcement Learning from Human Feedback)虽然提升了模型性能,但这种提升是基于人类反馈的,因此不能简单地认为它能创造出超越人类的结果。
Karpathy对RLHF的批判并非首次,他曾与Yann LeCun等人一起质疑RLHF强化学习的意义。他们认为,RLHF只是勉强算作强化学习,而且对于LLM(Large Language Models)来说,RLHF的适用性令人惊讶,因为训练的RM(Reward Model)只是以相同的方式进行直觉检查,而不是解决问题的实际目标。
此外,Karpathy还提到,不能长时间运行RLHF,因为模型会学会适应游戏奖励模型,推理出一些不正常的Token。与此同时,VRAIN和剑桥大学研究人员的Nature论文评测发现,大模型在一些简单任务上无法解决,而在复杂任务上则无法回避错误答案。
尽管大模型的参数和训练数据不断增加,性能也在提升,但从基础机制来看,它们似乎并不可靠。Karpathy提出,如果RLHF不适用,可以考虑基于规则的奖励(Rule-Based Rewards,RBR)作为新的奖励机制,以帮助大模型准确遵循指令。RBR不仅适用于安全训练,还可以适应各种任务,定义所需行为,为特定应用程序定制模型响应的个性或格式,为大模型性能突破提供新思路。
原文和模型
【原文链接】 阅读原文 [ 1187字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★☆☆☆☆


相关文章




