AI胡说八道这事,终于有人管了?
文章摘要
【关 键 词】 AI幻觉、检测方法、数据集、探针训练、高风险域
AI大模型的幻觉问题在高风险领域应用中愈发棘手,现有幻觉检测技术存在局限,而苏黎世联邦理工学院和MATS的新研究提出了低成本、可扩展的检测方法。
揭示幻觉根源与现状:OpenAI论文指出大模型幻觉问题根源在于奖励机制,标准训练和评估程序更倾向奖励猜测,而非承认不确定。随着AI大模型在高风险领域应用加深,幻觉问题更棘手,不少研究者发力寻找原因和研究检测技术,但现有检测技术仅适用于简短事实查询,或需借助昂贵外部资源验证。
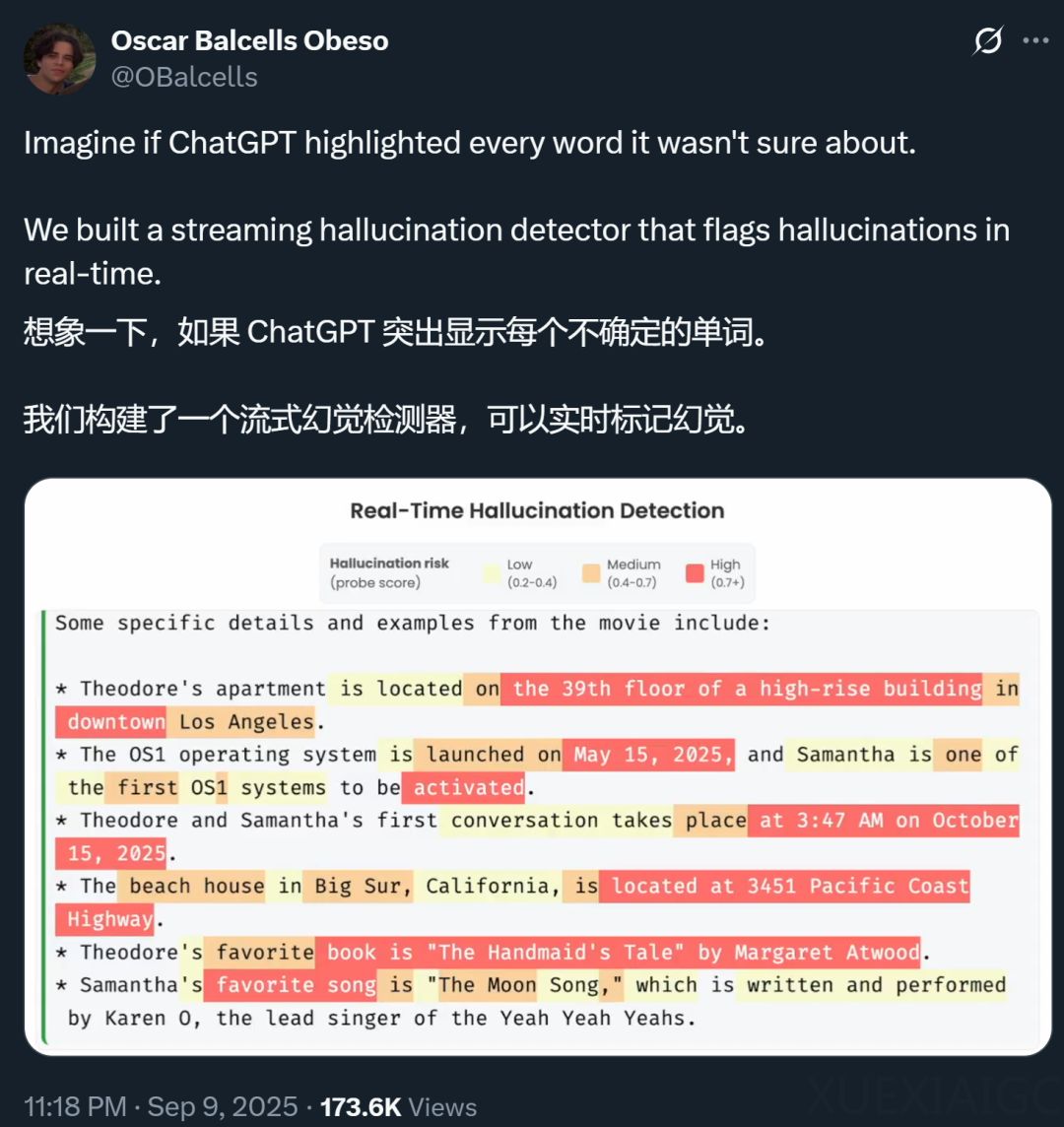
新检测方法核心及优势:新研究提出的检测方法核心是精准识别实体级幻觉,能自然映射到token级标签,实现实时流式检测。主要通过token级探针检测幻觉实体,线性探针在长文本生成场景性能远超基于不确定性的基线方法,LoRA探针进一步提升性能,且在短文本场景和分布外推理领域也表现出色。研究人员开发高效标注流程,利用网络搜索验证实体并为token标注,基于此数据集训练出的幻觉分类器,在四种主流模型家族评估中全面超越现有基准方法,尤其处理长篇回复时效果更佳,还具备超越实体检测的泛化能力,可识别逻辑错误。
数据集构建与标注:为训练token级检测分类器,构建数据集分两步。一是在LongFact数据集基础上创建LongFact++提示集,诱导大模型生成富含实体的长文本;二是专注标注实体,使用Claude 4 Sonnet模型自动完成标注流程,将实体标记为“Supported”“Not Supported”或“Insufficient Information”。经验证,人类标注员与大模型自动标注结果一致性为84%,在受控数据集中召回率为80.6%,假阳性率为15.8%。
训练探针与实验结果:探针由线性“价值头”和可选LoRA适配器组成,训练总损失函数结合探针损失和正则化项,采用混合损失函数聚焦关键错误信号。实验结果显示,在长文本和短文本设置中,token级探针均优于基线方法,LoRA探针表现更佳。在次要模型上结果相似,但长文本上的R@0.1最高约为0.7,表明该方法虽有实际收益,但在广泛应用于高风险场景前仍需改进。研究团队已公开发布数据集推动后续研究。
原文和模型
【原文链接】 阅读原文 [ 2105字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★★


相关文章




