文章摘要
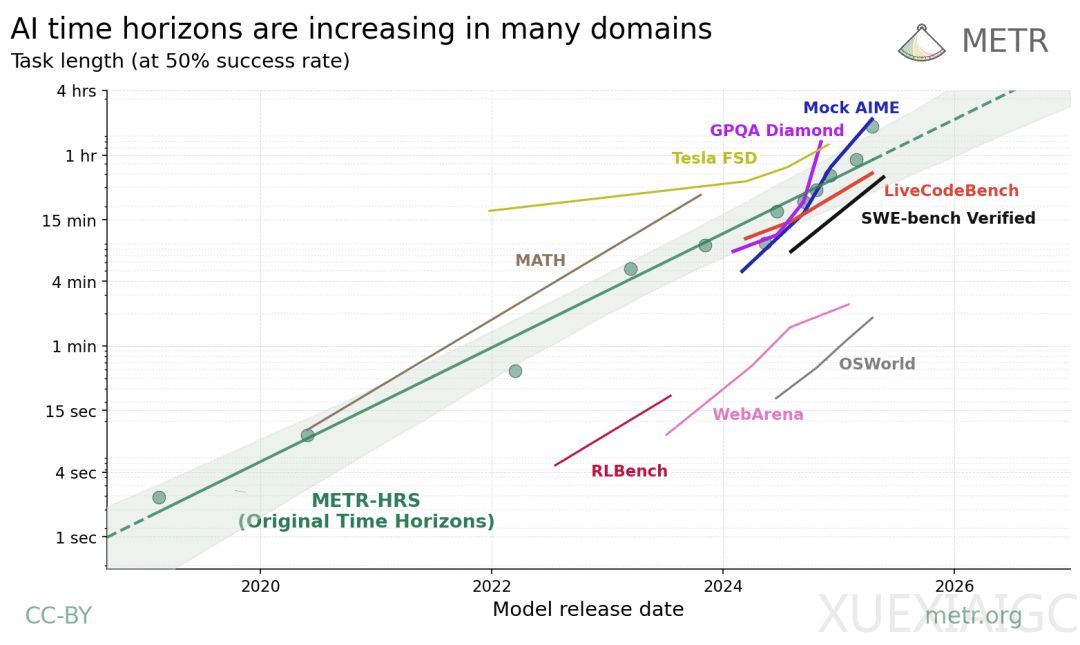
根据非营利研究机构METR最新发布的报告,AI智能体的能力呈现出一种“摩尔定律”式的增长趋势,平均每七个月其可完成任务的time horizon就会翻一番。这一规律已在9项基准测试中得到了验证,涉及编程、数学、计算机使用、自动驾驶等领域。报告指出,在软件开发、数学竞赛、科学问答等任务中,智能体已能完成相当于人类花费50–200分钟才能完成的任务,并且这种能力还在快速提升——大约每2–6个月就能翻一番。在计算机操作任务中,虽然任务时长较短,但增长率与软件开发等任务一致。自动驾驶任务的性能增长速度则较慢,约20个月翻一番。在视频理解任务中,模型能够在时长1小时的视频上取得50%的成功率。
METR将评估范围拓展至更广泛的领域,并继续追问一个关键问题:AI的能力,是否能在更广泛的任务中,以time horizon翻倍的方式不断跃升?time horizon是指智能体在任务上可稳定完成的时间跨度,time horizon越长≈任务越难≈需要更多策略推理与计划能力≈智能体的智能水平越高。报告选取了9个benchmark,包括软件开发、计算机使用、数学竞赛、编程竞赛、科学问答、视频理解、自动驾驶和机器人仿真。对每个benchmark,METR构造了概率模型来估算智能体的time horizon,采用最大似然估计(MLE)或简化估计方法,处理不同benchmark的标签粒度以估算出每个领域AI随时间的time horizon增长曲线。
研究发现,智能体的能力按月翻番,当前主流的几家大模型在METR任务上的表现一直高于趋势水平,翻倍时间快于7个月,在9个基准测试的翻倍时间中位数约为4个月(范围为2.5至17个月)。然而,time horizon并非对于所有的基础测试中都重要。由于有些基准中难题的难度要远大于简单题,而在另一些基准中,难题却和简单题相差无几。因此,对于智能体来说,在这些基准测试中time horizon并不能完全反映其性能。例如,LeetCode(LiveCodeBench)和数学问题(AIME)的难度要远高于简单问题,但长视频上的Video-MME问题并不比短视频上的难多少。可见,智能体的性能并不只是看“会更多技巧”,而是看是否能处理更长、更复杂任务。
从几秒、几分钟,到几十分钟、几小时,智能体的可处理范围正在跨越级别提升;如果翻倍趋势持续,未来几年内可能看到AI完成“几天→几周”的任务成为可能。总结这一研究可以看到一个很清楚的规律:从代码推理到数学竞赛,从GUI控制到自动驾驶,没有一个任务域显示出智能增长的“乏力”。在多数场景中,AI正全速向更大跨度、更深记忆、更复杂规划演进。
原文和模型
【原文链接】 阅读原文 [ 1229字 | 5分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆


相关文章




