作者信息
【原文作者】 AI技术实战
【作者简介】 分享AI技术、AI工具、AIGC,所有内容均为作者实际操作所得,欢迎交流。
【微 信 号】 AI-beautiful-life
文章摘要
【关 键 词】 OpenAI、语音识别、Whisper、部署教程、Docker
OpenAI最近开源了一个名为Whisper的语音识别项目,该项目能够将视频和语音文件转换为文字。Whisper的性能被认为可以与科大讯飞的收费产品相媲美,而且它不需要GPU支持,可以在普通配置的计算机上运行。Whisper项目的源代码托管在GitHub上,地址为:https://github.com/openai/whisper。
然而,本文的重点不在于按照官方文档进行部署,而是介绍如何使用另一个项目(https://github.com/ahmetoner/whisper-asr-webservice)在Whisper的基础上提供Web界面,并且支持通过Docker进行部署,这使得部署过程变得非常简便。
以下是基于Windows系统的部署操作步骤:
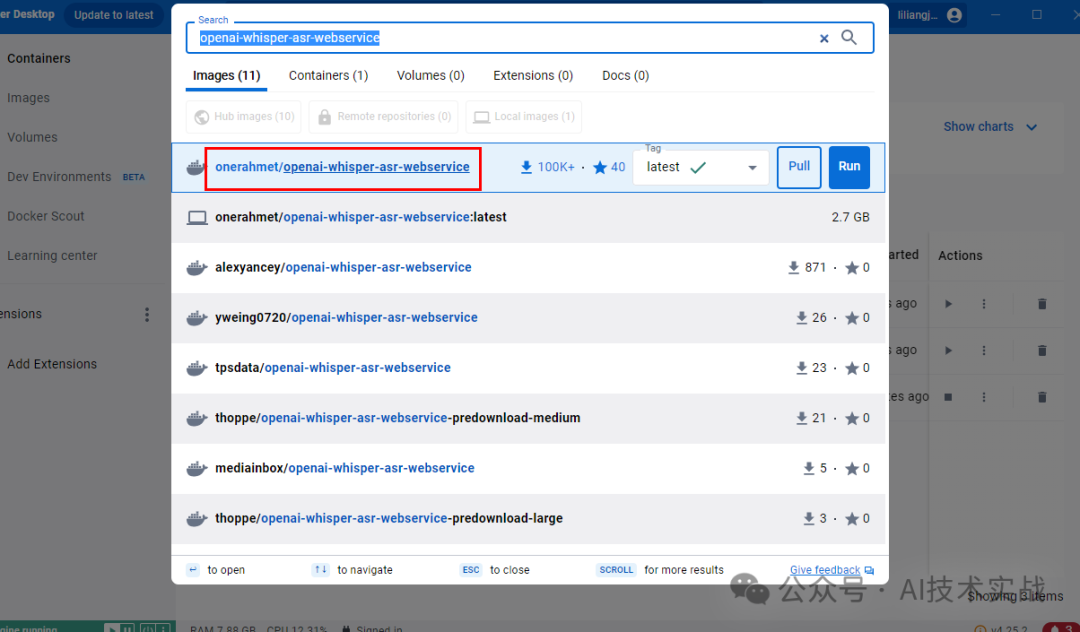
一、下载镜像
通过Docker搜索openai-whisper-asr-webservice,并选择第一个镜像进行pull操作。
二、启动
使用以下命令启动服务:
“`
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest
“`
启动后,通过浏览器访问 http://localhost:9000/。初次访问时会下载模型,需要稍等片刻。成功部署后,可以看到Web界面。
三、使用
该项目提供了两个HTTP接口:
1. /asr:语音识别接口,上传语音或视频文件,输出文字。
2. /detect-language:语言检测接口,上传语音或视频文件,输出语言。
3.1 英文音频转文字
使用英文MP3音频文件测试语音识别效果。转换完成后,可以在响应体中看到转换结果。
3.2 中文视频转文字
操作与英文音频转换类似,只是上传的是视频文件。转换后的结果可以对照视频进行检查。
3.3 语言检测
该接口用于检测语音文件中的语言,对于大文件,只会检查前30秒的内容。
四、修改模型
官方提供了不同大小的模型,包括模型大小、所需内存和相对速度的对比。可以根据需要选择合适的模型。
五、模型缓存
为了避免每次运行Docker命令时都重新下载模型,可以将模型保存到宿主机的指定目录下,加快后续的访问速度。
六、接口参数
介绍了接口的各种参数,包括编码、任务类型、语言、提示、时间戳和输出格式等。
总的来说,这篇文章提供了一个简洁的教程,指导用户如何通过Docker部署和使用OpenAI的Whisper语音识别服务。
原文信息
【原文链接】 阅读原文
【原文字数】 1466
【阅读时长】 5分钟

相关文章





