40位数学家组成8队与o4-mini-medium比赛,6队败北
文章摘要
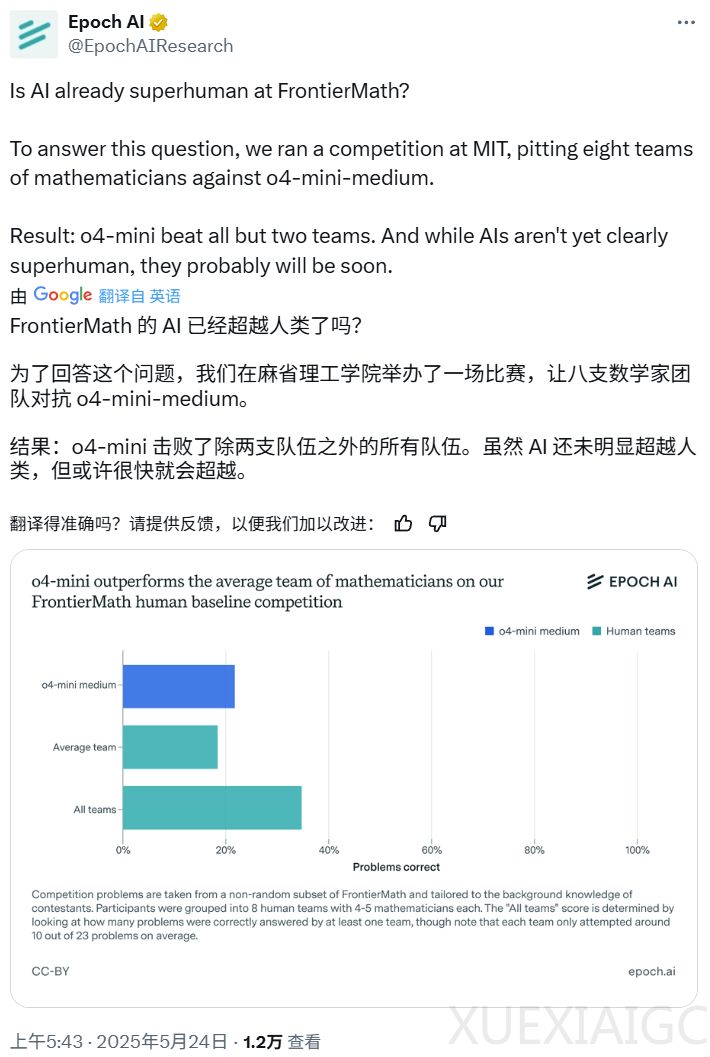
Epoch AI 最近组织了一场人机数学竞赛,邀请了40位数学家组成8支队伍,与OpenAI的o4-mini-medium模型进行对决。竞赛题目来自高难度的FrontierMath数据集,旨在测试AI在数学推理能力上的极限。结果显示,AI以6:2的比分击败了人类队伍,o4-mini-medium在竞赛中得分为22%,高于人类团队的平均水平(19%),但低于所有团队的总得分(35%)。尽管AI尚未达到明显的超人类水平,但Epoch AI认为它可能很快会实现这一目标。
FrontierMath数据集包含300道题目,难度从本科生高年级水平到菲尔兹奖得主都觉得难的水平不等。竞赛中,人类团队需要在4.5小时内解答23道题,过程中可以使用互联网。AI的表现虽然优于人类团队的平均水平,但并未在所有团队的综合得分上占据优势。值得注意的是,AI成功解答的问题都至少有一支人类团队成功解答,这表明AI在特定领域的推理能力已经接近人类专家。
Epoch AI对竞赛结果进行了详细分析,指出人类基准的定义较为模糊。竞赛中的题目难度分布与完整的FrontierMath数据集不同,因此人类基准的得分可能在30%到50%之间。此外,人类团队的表现可能被低估,因为竞赛时间有限,而AI完成每道题的时间通常为5-20分钟,人类则需要更长时间。Epoch AI认为,尽管AI在竞赛中的表现接近人类,但其推理方式与人类是否相同仍不明确。
竞赛还揭示了人类与AI在长期扩展行为上的差异。研究表明,人类的表现能够持续提升,而AI的表现在一段时间后可能会停滞不前。此外,FrontierMath上的问题并不直接代表实际的数学研究,因此竞赛结果在评估AI的数学推理能力时具有一定的局限性。尽管如此,Epoch AI认为这场竞赛为建立人类基准提供了有价值的参考,有助于将FrontierMath的评估置于实际情境中。
总的来说,这场人机数学竞赛展示了AI在数学推理能力上的显著进步,尽管尚未完全超越人类,但其潜力不容忽视。Epoch AI预计,AI可能在不久的将来在数学领域实现明确的超人类水平。
原文和模型
【原文链接】 阅读原文 [ 2105字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



