3B模型长思考后击败70B!HuggingFace逆向出o1背后技术细节并开源
文章摘要
【关 键 词】 小模型、性能提升、计算扩展、测试时优化、多样性验证
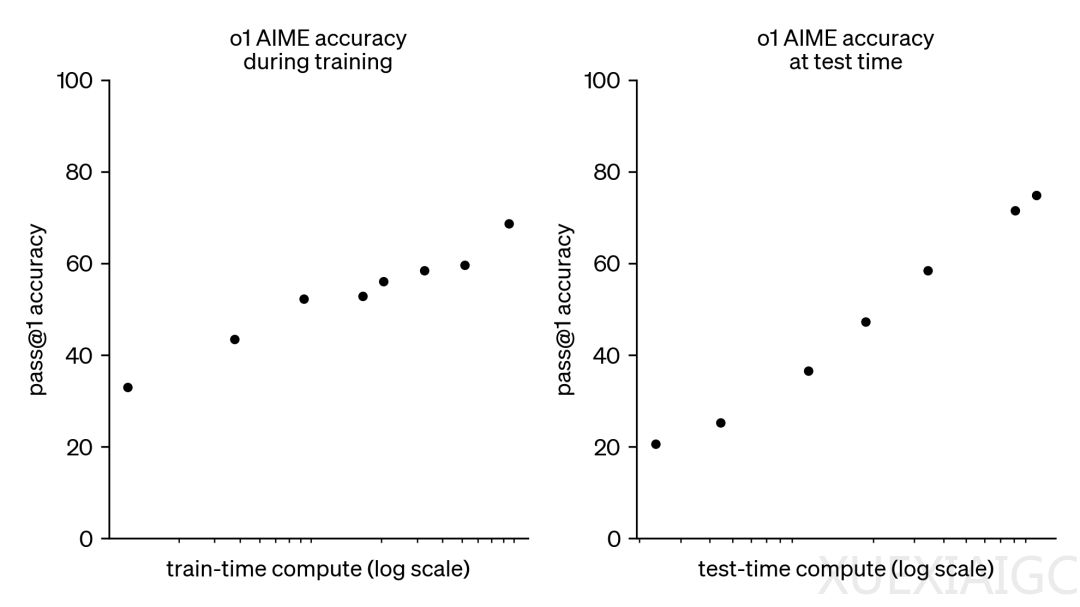
近期,小模型的研究受到关注,因为通过实用技巧,它们在性能上有望超越更大规模的模型。这种趋势的背景是大语言模型训练所需的资源变得异常昂贵,而测试时计算扩展(test-time compute scaling)作为一种互补方法,不依赖于预训练预算,而是通过动态推理策略让模型在难题上“思考更长时间”。DeepMind的研究表明,可以通过迭代自我改进或使用奖励模型在解决方案空间上进行搜索等策略来实现测试时计算的最佳扩展。HuggingFace通过逆向工程和复现这些结果,介绍了计算最优扩展、多样性验证器树搜索(DVTS)和搜索与学习等技术,这些技术提升了测试时开放模型的数学能力,并提高了多样性和性能。
在实践中,给小模型足够的“思考时间”,它们在MATH-500基准上超越了更大的模型。HuggingFace的实验设置包括使用Llama模型和过程奖励模型(PRM)在MATH-500子集上进行评估。实验结果表明,多数投票方法比贪婪解码基线有显著改进,但收益在N=64后趋于平稳。Best-of-N方法使用奖励模型来确定最合理的答案,其中加权Best-of-N始终优于普通Best-of-N。集束搜索作为一种结构化搜索方法,与PRM结合使用时,可以优化问题解决中中间步骤的生成和评估。DVTS作为集束搜索的扩展,旨在提高N较大时的多样性,它在N较大时提高了简单/中等问题的性能。
计算-最优扩展策略可以根据问题难度和测试时计算预算选择最佳的搜索方法和超参数。将这种方法扩展到更大的模型,如Llama 3.2 3B Instruct,结果显示计算-最优的扩展效果非常好,3B模型的性能超过了Llama 3.1 70B Instruct。未来的方向包括强化验证器、自我验证、将思维融入过程、搜索作为数据生成工具,以及开发和共享更多的PRM。这些探索揭示了利用基于搜索的方法的潜力和挑战,为小模型的性能提升提供了新的思路。
原文和模型
【原文链接】 阅读原文 [ 4714字 | 19分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


