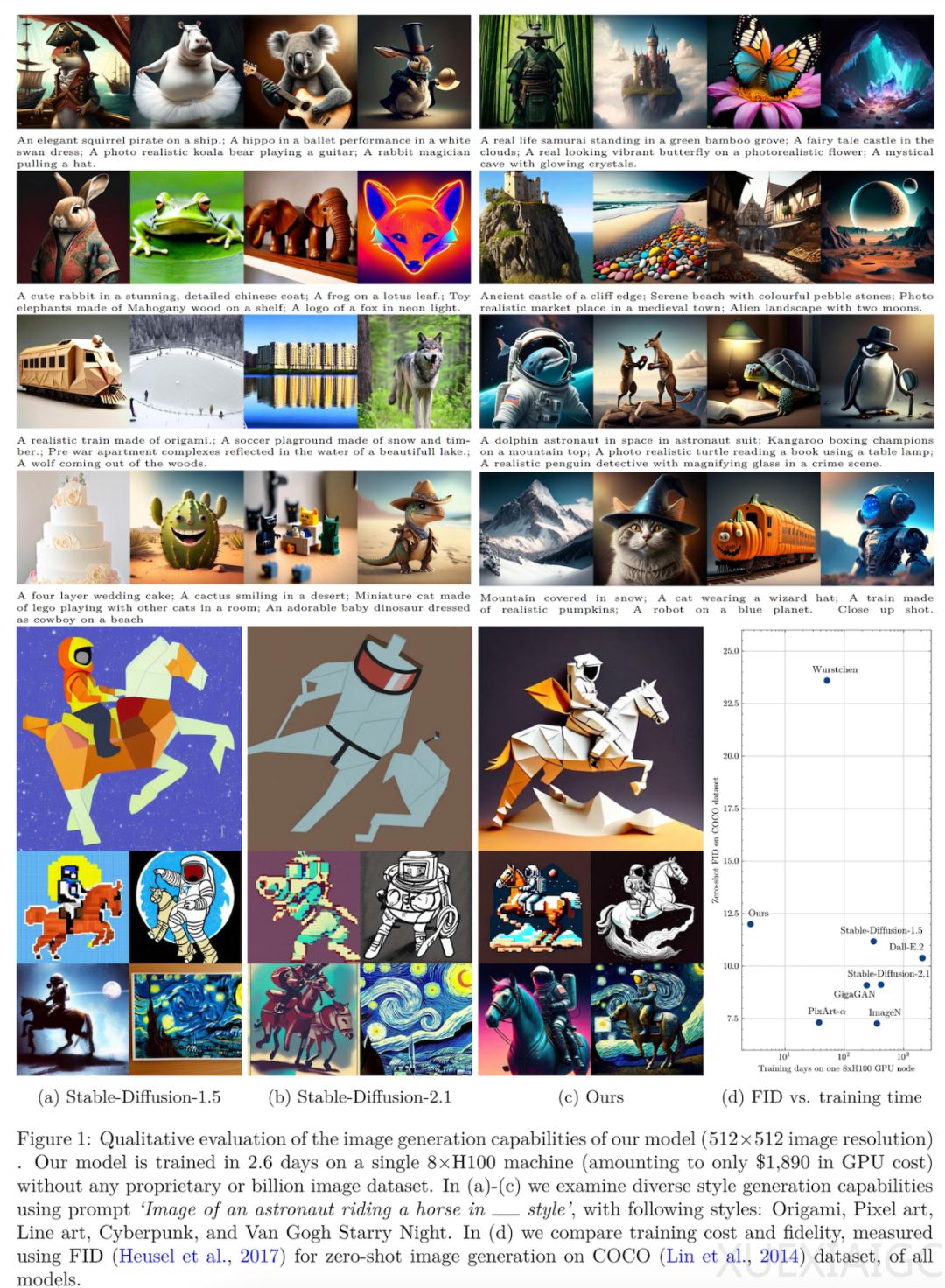
1890美元,就能从头训练一个还不错的12亿参数扩散模型
文章摘要
【关 键 词】 文本到图像、低成本训练、延迟掩蔽、稀疏Transformer、扩散模型
Sony AI等机构的研究者开发了一种低成本的端到端pipeline,用于训练文本到图像的扩散模型,显著降低了训练成本,同时不需要访问数十亿张训练图像或专有数据集。该研究的主要目标是在训练过程中减少transformer处理每张图像的有效patch数,通过在transformer的输入层随机掩蔽掉部分token来实现。然而,现有的掩蔽方法在高掩蔽率下无法不大幅降低性能。为了解决这个问题,研究者提出了一种延迟掩蔽策略,所有patch都由轻量级patch混合器进行预处理,然后再传输到扩散transformer。这种策略允许未掩蔽的patch保留有关整个图像的语义信息,并能在非常高的掩蔽率下可靠地训练扩散transformer,同时不会产生额外的计算成本。
研究者还利用了Transformer架构的最新进展,如逐层缩放和使用MoE的稀疏Transformer,以提高大规模训练的性能。在3700万张图像的组合数据集上,以1890美元的成本训练了一个11.6亿参数的稀疏transformer,在COCO数据集上的零样本生成中实现了12.7 FID,这与现有最先进方法相比具有竞争力的FID和高质量生成,但成本仅为1/15。
为了降低计算成本,研究者提出了patch掩蔽方法,要求在输入主干transformer之前丢弃大部分输入patch,从而使transformer无法获得被掩蔽patch的信息。然而,高掩蔽率会显著降低transformer的整体性能。为了保留所有patch的语义信息,研究者提出了延迟掩蔽策略,使用patch-mixer对patch嵌入进行预处理,使未被掩蔽的patch能够嵌入整个图像的信息。patch-mixer是一个轻量级的transformer,可以融合单个patch嵌入。
在实验中,研究者采用了扩散Transformer的两个变体DiT-Tiny/2和DiT-Xl/2,并比较了不同的掩蔽策略。结果表明,延迟掩蔽方法在多个指标上都实现了更好的性能,尤其是在高掩蔽率下,性能差距会扩大。此外,研究者还利用了layer-wise scaling方法在扩散transformer的掩蔽训练中具有更好的拟合效果。
总的来说,这项研究通过开发一种低成本的端到端pipeline,显著降低了文本到图像扩散模型的训练成本,同时实现了具有竞争力的性能。这对于大规模扩散模型的开发具有重要意义,有望推动相关技术的发展和应用。
原文和模型
【原文链接】 阅读原文 [ 2883字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


