12年前上手深度学习,Karpathy掀起一波AlexNet时代回忆杀,LeCun、Goodfellow等都下场
文章摘要
【关 键 词】 深度学习、大模型时代、AlexNet、编程语言、性能优化
自2012年AlexNet在ImageNet竞赛中取得突破性成绩,标志着深度学习革命的开始,至今已过去12年。AI研究科学家Andrej Karpathy的一条帖子引发了AI界多位知名人士的回忆,包括图灵奖得主Yann LeCun和GAN之父Ian Goodfellow。这条帖子的浏览量超过63万次,显示了其引起的广泛关注。
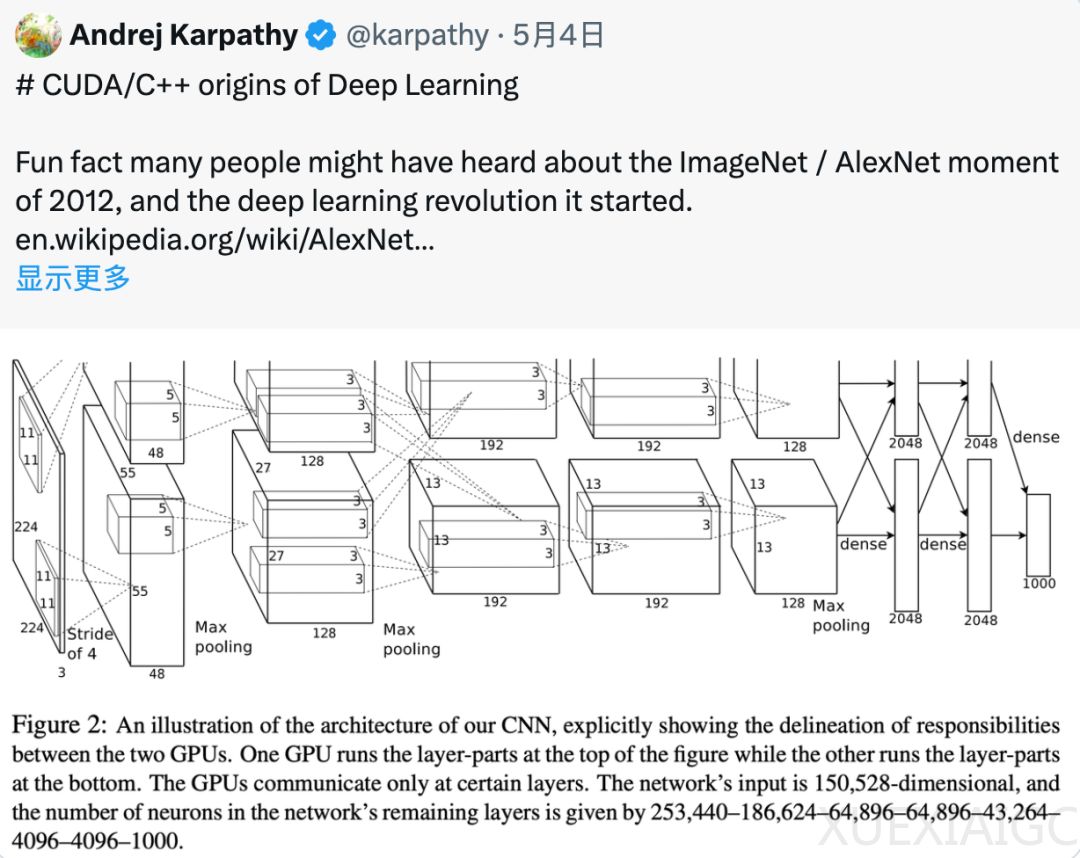
Karpathy在帖子中提到,支持AlexNet胜出的代码是由Alex Krizhevsky亲手用CUDA/C++编写的,这个代码仓库名为cuda-convnet,当时托管在Google Code上。他还提到,尽管Google Code已关闭,但在GitHub上可以找到基于原始代码的新版本。Karpathy回忆说,AlexNet是最早将CUDA用于深度学习的例子之一,它使用了多GPU系统和模型并行技术,这在当时是非常先进的。
在2012年,大多数深度学习研究都是在Matlab中进行,运行在CPU上,主要是在小规模数据集上迭代学习算法、网络架构和优化思路。而AlexNet的作者们选择了一条不同的道路,他们没有纠结于算法细节,而是采用了一个标准的卷积神经网络,将其规模做大,并在大规模数据集ImageNet上训练,使用CUDA/C++实现整个系统。这种从底层编程的方式虽然复杂繁琐,但能最大限度地优化性能,充分发挥硬件计算能力,成为深度学习历史上的一个转折点。
文章中还提到了其他研究人员在2012年前后使用的工具和语言,包括Torch、Theano、Matlab和Python。这些讨论显示了当时深度学习领域的多样性和转变。一些研究人员已经意识到深度学习需要更大的规模和更强的计算能力,GPU是一个很有前景的方向。
Karpathy最后感慨,尽管现在有了高级框架,但在追求极致性能时,仍然需要回到最底层,亲自编写CUDA/C++代码。这种”back to the basics”的做法与当年AlexNet的做法有着异曲同工之妙。文章最后提出了一个问题,询问当时国内的研究者们都使用什么工具,鼓励读者参与讨论。
原文和模型
【原文链接】 阅读原文 [ 2005字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4
【摘要评分】 ★★★★★


相关文章



