文章摘要
多模态大语言模型在实际应用中展现出卓越性能,但其计算开销和显存占用问题仍然是关键瓶颈。KV cache机制通过显存换取计算效率,但随着输入数据规模的增大,显存占用迅速增加,限制了吞吐量。为了解决这一问题,CalibQuant团队提出了一种极端的1比特KV cache量化方案,结合后缩放和校准技术,显著降低了显存和计算成本,同时几乎不损失模型性能。该方法在InternVL-2.5模型上实现了10倍的吞吐量提升,并具有即插即用的特性,能够无缝集成到现有多模态大语言模型中。
当前的多模态大语言模型在处理大尺寸、高分辨率的图像或视频数据时,KV cache的显存占用与输入长度成正比,成为限制吞吐量的主要因素。尽管已有一些针对LLM KV cache量化的方法,但这些方法未针对多模态问题中的视觉冗余进行优化,无法在1比特极限情况下使用。CalibQuant通过分析多模态模型中的视觉KV cache冗余,设计了适合多模态模型的量化方案,解决了这一难题。
CalibQuant的核心方法包括通道维度量化和后缩放优化。通道维度量化通过在通道维度上细化统计范围,减少量化对模型性能的影响。后缩放优化则通过重排计算顺序,减少存储需求并提高计算效率。这种方法避免了全精度反量化计算过程,确保了低比特反量化执行的高效性。此外,针对1比特量化后可能出现的极端值问题,CalibQuant提出了一种量化后校准方法,通过调整softmax之前的注意力分数,有效缓解了量化带来的失真。
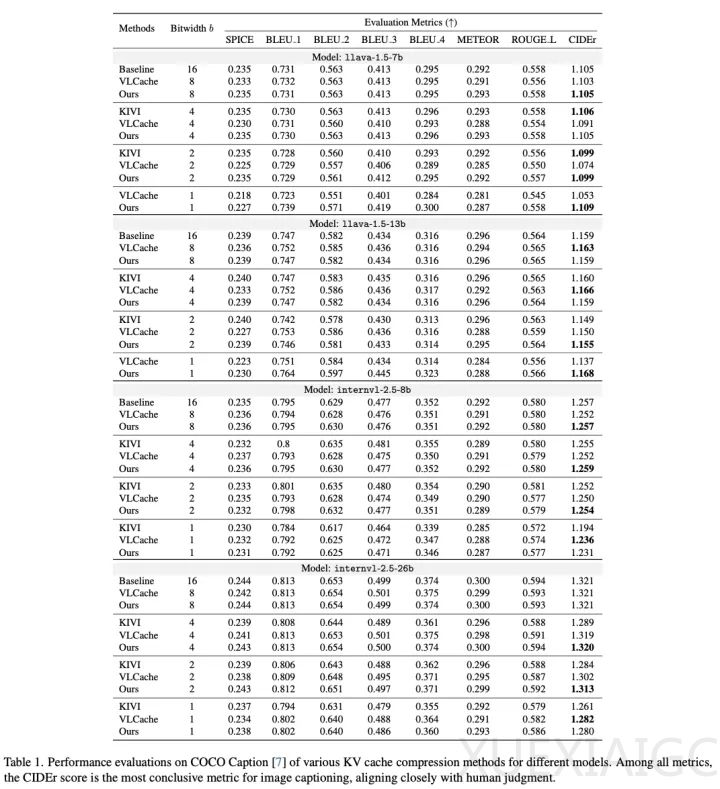
实验结果表明,CalibQuant在LLaVA和InternVL模型系列上,针对COCO Caption、MMBench-Video和DocVQA等基准任务,均表现出优于其他量化方法的性能。例如,在LLaVA-1.5-7B模型上,CalibQuant在1比特量化下达到了1.109的CIDEr分数,超过了VLCache的1.053。此外,runtime分析显示,CalibQuant在1比特量化下,相比全精度模型,吞吐量提升了约10倍,显著提高了解码效率。
总结来看,CalibQuant通过创新的量化策略和校准技术,解决了多模态大语言模型在部署过程中的显存和计算瓶颈问题。该方法不仅显著提升了吞吐量,还保持了模型性能,为多模态大语言模型的高效部署提供了新的解决方案。
原文和模型
【原文链接】 阅读原文 [ 2320字 | 10分钟 ]
【原文作者】 AI前线
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




