文章摘要
【关 键 词】 开源模型、强化学习、训练优化、顿悟时刻、基准性能
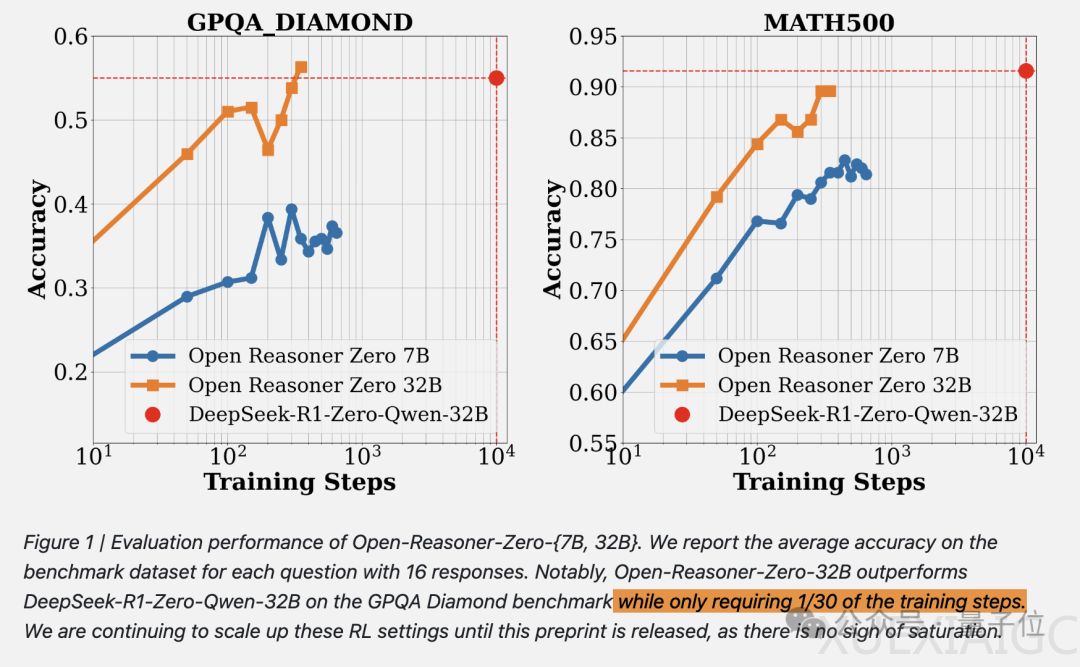
阶跃星辰与清华大学联合发布的Open Reasoner Zero(ORZ)模型在强化学习训练方法上取得突破性进展。该研究采用极简主义方法,仅使用带有GAE的原版PPO算法和基于规则的奖励函数,在1/30训练步骤内即达到与DeepSeek-R1-Zero 671B模型相当的推理性能,证明复杂奖励函数并非必要。训练过程中未依赖KL正则化技术,为强化学习规模化应用提供了新思路。
实验数据显示,当训练步骤达到680步时,模型在奖励值、反思能力和响应长度三个维度同时出现显著提升,这一现象与DeepSeek-R1-Zero论文中描述的”顿悟时刻“高度相似。研究团队发现,训练数据的规模与多样性对模型性能具有决定性影响:在MATH等有限数据集上训练会快速进入平台期,而大规模多样化数据集可实现持续性能提升且未见饱和迹象。
在模型架构方面,基于Qwen2.5-Base-7B的实验表明,所有基准测试均会在特定阶段经历奖励和响应长度的突变式增长。值得注意的是,平均正确反思长度始终高于平均响应长度,这一特性可能对提升模型推理能力具有关键作用。最终模型在MMLU和MMLU_PRO基准测试中,无需额外指令微调即超越Qwen2.5 Instruct版本。
技术实现层面,研究团队采用GAE λ=1和折扣因子γ=1的关键参数设置,通过PPO算法成功扩展了RL训练规模。开源内容包含完整的训练数据、代码、论文及模型,采用MIT许可证开放使用。项目发布48小时内即获得700+ GitHub星标,显示出业界对该技术路径的高度关注。目前该研究仍处于持续更新状态,团队将持续优化训练方法和模型性能。
原文和模型
【原文链接】 阅读原文 [ 760字 | 4分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-r1
【摘要评分】 ★☆☆☆☆


相关文章



