文章摘要
【关 键 词】 AI技术、CUDA平台、跨平台、PyTorch、GPU竞争
Nvidia在AI行业中的影响力不容小觑,其推出的CUDA平台为AI硬件提供了强大的软件支持。尽管CUDA并非开源,但其免费提供且由Nvidia控制,使得其他公司难以在高性能计算(HPC)和通用人工智能(GenAI)市场抢占份额。
为了突破CUDA的壁垒,出现了SCALE这一新的解决方案。SCALE是英国公司Spectral Compute开发的GPGPU工具链,允许在AMD GPU上本地运行CUDA程序。SCALE利用开源LLVM组件,无需修改即可编译适用于AMD GPU的CUDA源代码,相较于其他转换项目具有显著优势。
SCALE通过与NVIDIA CUDA工具包的兼容性,允许用户直接使用CUDA程序,甚至处理依赖于NVPTX汇编的程序。它已在多个软件中成功测试,包括Blender、Llama-cpp、XGboost等,并在RDNA2和RDNA3 GPU上进行了测试。SCALE的推出旨在与NVIDIA CUDA完全兼容,使用户无需维护多个代码库或牺牲性能来支持多个GPU供应商。
AMD也在通过多种方式跨越CUDA壁垒。AMD的HIP CUDA转换工具允许开发人员为AMD和NVIDIA GPU创建可移植的应用程序。此外,AMD还与第三方合作推出了ZLUDA项目,使AMD GPU能够运行未经修改的二进制CUDA应用程序。尽管AMD对ZLUDA的资助已经结束,但该项目仍在继续。
英特尔也在努力推动跨平台解决方案。英特尔首席技术官Greg Lavender提出使用LLM和Copilot技术将CUDA代码转换为SYCL,以在其他AI加速器上运行。SYCL是一个跨架构抽象层,为英特尔的并行C++编程语言提供支持。英特尔还参与了“统一加速基金会”(UXL),旨在开发一款开源软件套件,使代码能够在任何机器和任何芯片上运行。
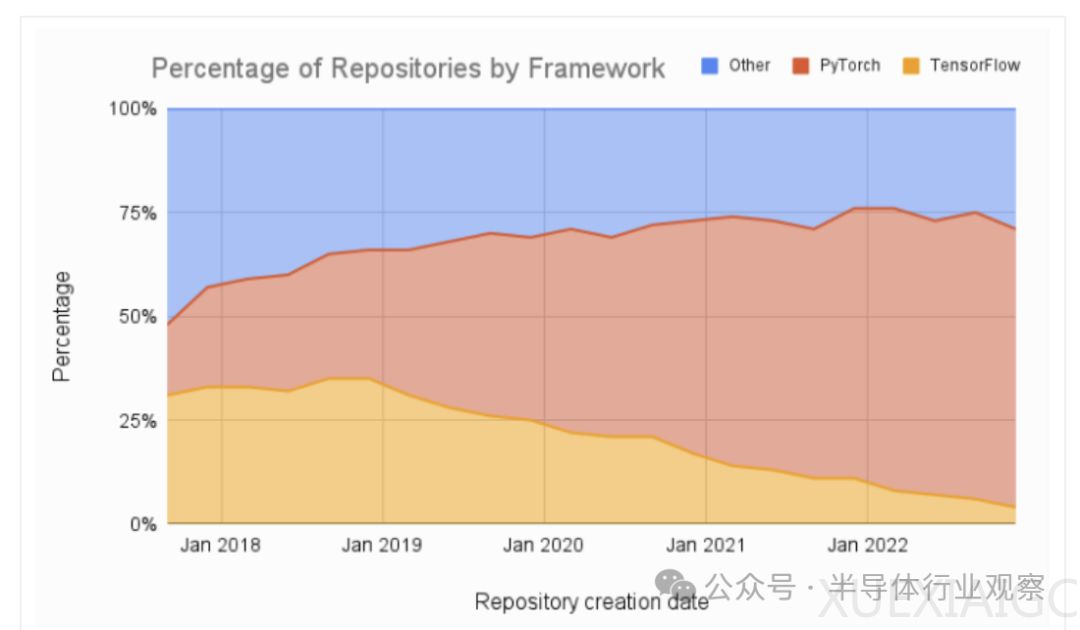
在AI领域,PyTorch逐渐取代TensorFlow成为首选工具。PyTorch是一个开源的机器学习库,用于开发和训练基于神经网络的深度学习模型。PyTorch的底层调用CUDA,但用户与底层GPU架构隔离,使得跨越AMD GPU的CUDA壁垒变得简单。AMD ROCm提供了PyTorch版本,进一步推动了跨平台解决方案的发展。
总之,随着SCALE、HIP、ZLUDA、SYCL和PyTorch等解决方案的出现,Nvidia CUDA在AI和HPC市场的主导地位正面临挑战。这些方案为开发人员提供了更多选择,使他们能够在不同GPU供应商的硬件上运行和优化他们的应用程序。
原文和模型
【原文链接】 阅读原文 [ 2758字 | 12分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



