文章摘要
【关 键 词】 文生视频、扩散模型、对角去噪、潜在分割、前瞻去噪
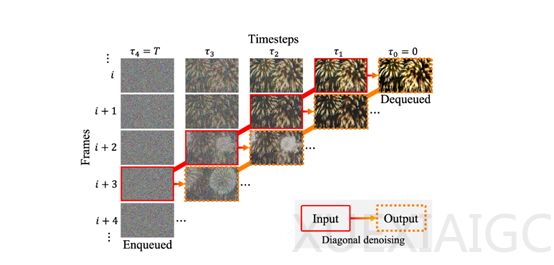
韩国首尔国立大学研究团队开发的FIFO-Diffusion模型,通过创新技术解决了传统文生视频模型在生成长视频时存在的质量下降与连贯性不足问题。传统模型因训练时仅能处理有限帧数,导致生成超出训练时长的视频时效果受限,而FIFO-Diffusion引入的对角线去噪技术,通过模拟工厂流水线机制,以队列形式管理视频帧的噪声水平,实现了无需重新训练即可生成无限长度视频的能力。队列头部完全去噪的帧被移出,尾部则持续加入新噪声帧,确保每帧生成时均能参考足够的前序帧,从而维持视频流畅度与逻辑一致性。
该模型的核心模块——对角线去噪,通过维护按时间顺序排列且噪声水平递增的帧队列,将去噪过程分解为连续步骤。在每一步迭代中,队列头部的低噪声帧被移除,尾部新增高噪声帧,形成动态平衡。然而,传统扩散模型训练时通常针对统一噪声水平的帧进行优化,而实际推理中需处理不同噪声水平的帧,导致性能差异。为此,研究团队提出潜在分割与前瞻去噪两大优化模块。
潜在分割模块通过将连续帧序列划分为多个噪声水平相近的块,缩小了训练与推理的差距。每个块内的帧仅需处理较小范围的噪声变化,降低了模型复杂度,同时支持多GPU并行计算。这种分块策略不仅提升了去噪精度,还将计算效率提高了数倍,使得生成长视频的耗时大幅缩减。队列被等分为多个子块后,模型可独立处理各块,充分利用硬件资源加速生成过程。
前瞻去噪模块则通过引入未来帧信息优化当前帧的去噪结果。在初步对角线去噪后,模型利用队列中后续帧的状态进行二次修正,即使高噪声帧也能借助未来更干净的帧信息获得更准确的去噪效果。这一机制显著提升了视频的连贯性与细节还原度,尤其在复杂运动场景中,动态物体轨迹的平滑度得到明显改善。
原文和模型
【原文链接】 阅读原文 [ 1209字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-r1
【摘要评分】 ★★★☆☆


相关文章




