文章摘要
【关 键 词】 强化学习、贝叶斯、反思探索、推理模型、自适应
西北大学与Google、谷歌DeepMind团队提出了一种新的强化学习方法——贝叶斯自适应强化学习(BARL),旨在解决传统强化学习(RL)在反思探索方面的局限性。传统RL在测试阶段通常只依赖训练时学到的确定性策略,缺乏对新情境的适应能力。BARL通过引入贝叶斯框架,允许模型在推理过程中自适应地进行探索,从而在未知情境下保持高效表现。
BARL的核心思想是将反思性探索转化为贝叶斯自适应问题,通过建模环境的不确定性,让模型在决策时综合考虑历史观察和奖励反馈。这种方法打破了传统RL的马尔可夫假设,使得模型能够根据后验概率动态调整策略,平衡奖励最大化和信息获取。具体而言,BARL假设任务中存在多个可能的马尔可夫决策过程(MDP),模型通过不断更新对每个假设的信念,选择最优动作。这种机制鼓励模型在发现当前策略无效时,迅速切换到其他可能的策略,从而实现更高效的探索。
在合成任务中,BARL展现了显著的反思探索能力。当模型需要在3步内输出三个连续相同字符时,传统RL在遇到新字符时几乎完全失败,而BARL则通过反思和切换策略,成功适应了新情境。这一结果表明,BARL能够在测试阶段有效应对未知挑战,而传统RL则因过度依赖训练时的固定策略而表现不佳。
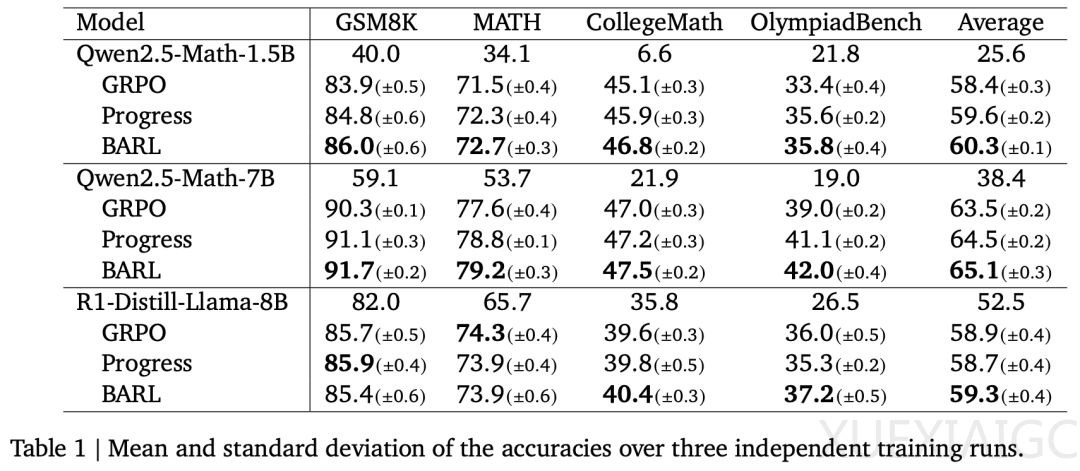
在数学推理任务中,BARL不仅在大部分基准上取得了更高的准确率,还显著减少了生成答案所需的token数量。这表明BARL的反思行为更具针对性,避免了无谓的冗长推理。此外,研究者发现,反思次数并非决定性能的唯一因素,基础模型往往出现大量无效的反思,而BARL的每一步动作都具备较高的贝叶斯价值,即要么对解题有帮助,要么带来了新的信息增益。
BARL的提出为推理模型提供了一种原则化的反思探索机制,使其能够在复杂任务中更高效地学习和适应。与传统RL相比,BARL不仅提升了模型的性能,还减少了资源消耗,为未来智能系统的开发提供了新的思路。研究团队已公开了训练代码和论文,供学术界进一步探索和应用。
原文和模型
【原文链接】 阅读原文 [ 2860字 | 12分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



