非Transformer架构站起来了!首个纯无注意力大模型,超越开源巨头Llama 3.1
文章摘要
【关 键 词】 技术创新、开源模型、文本生成、性能评估、智能系统
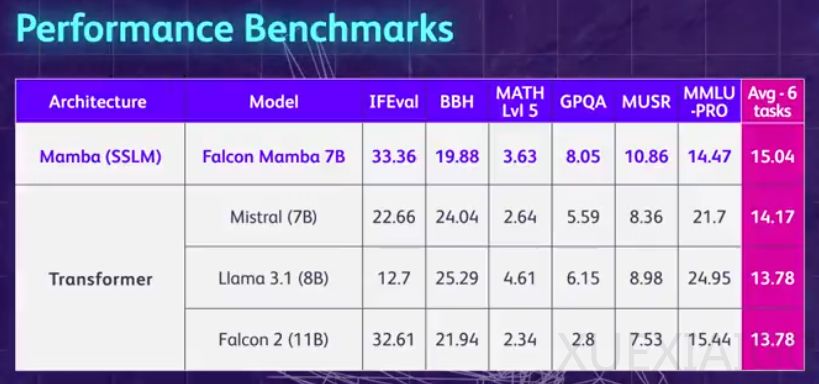
阿布扎比技术创新研究所(TII)发布了一款名为Falcon Mamba 7B的新型开源Mamba架构模型,该模型自2023年12月首次推出以来,已成为Transformer模型的有力竞争者。Falcon Mamba 7B的亮点在于无需增加内存存储即可处理任意长度的序列,并且能够在单个24GB A10 GPU上运行。该模型采用了新颖的状态空间语言模型(SSLM)架构,专门用于处理各种文本生成任务,并在一些基准测试中超越了同尺寸级别的领先模型,如Meta的Llama 3 8B、Llama 3.1 8B和Mistral 7B。
Falcon Mamba 7B包含四个变体模型:基础版本、指令微调版本、4bit版本和指令微调4bit版本。作为一个开源模型,它采用了基于Apache 2.0的许可证“Falcon License 2.0”,支持研究和应用目的。Falcon Mamba 7B是TII开源的第四个模型,也是首个采用Mamba SSLM架构的模型。
Falcon Mamba 7B的训练数据高达5500GT,主要由RefinedWeb数据集组成,并添加了来自公共源的高质量技术数据、代码数据和数学数据。模型采用多阶段训练策略,上下文长度从2048增加到8192。训练过程在256个H100 80GB GPU上完成,采用了3D并行与ZeRO相结合的策略。模型经过AdamW优化器、WSD学习率计划的训练,并在前50GT的训练过程中,batch大小从128增加到2048。整个模型训练花费了大约两个月时间。
在模型评估方面,Falcon Mamba 7B在单个24GB A10 GPU上能够适应更大的序列,理论上能够适应无限的上下文长度。在H100 GPU的设置中,模型以恒定的吞吐量生成所有token,并且CUDA峰值内存没有任何增加。在Arc、TruthfulQA和GSM8K基准测试中,Falcon Mamba 7B的得分分别为62.03%、53.42%和52.54%,超过了Llama 3 8B、Llama 3.1 8B、Gemma 7B和Mistral 7B。然而,在MMLU和Hellaswag基准测试中,Falcon Mamba 7B的表现则落后于这些模型。
TII首席研究员Hakim Hacid表示,Falcon Mamba 7B的发布代表着该机构向前迈出的重大一步,它激发了新的观点,并进一步推动了对智能系统的探索。目前,TII的Falcon系列语言模型下载量已超过4500万次,成为阿联酋最成功的LLM版本之一。Falcon Mamba 7B的论文即将发布。
原文和模型
【原文链接】 阅读原文 [ 1597字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




