文章摘要
【关 键 词】 液态神经网络、性能超越、内存效率、多模态应用、预览测试
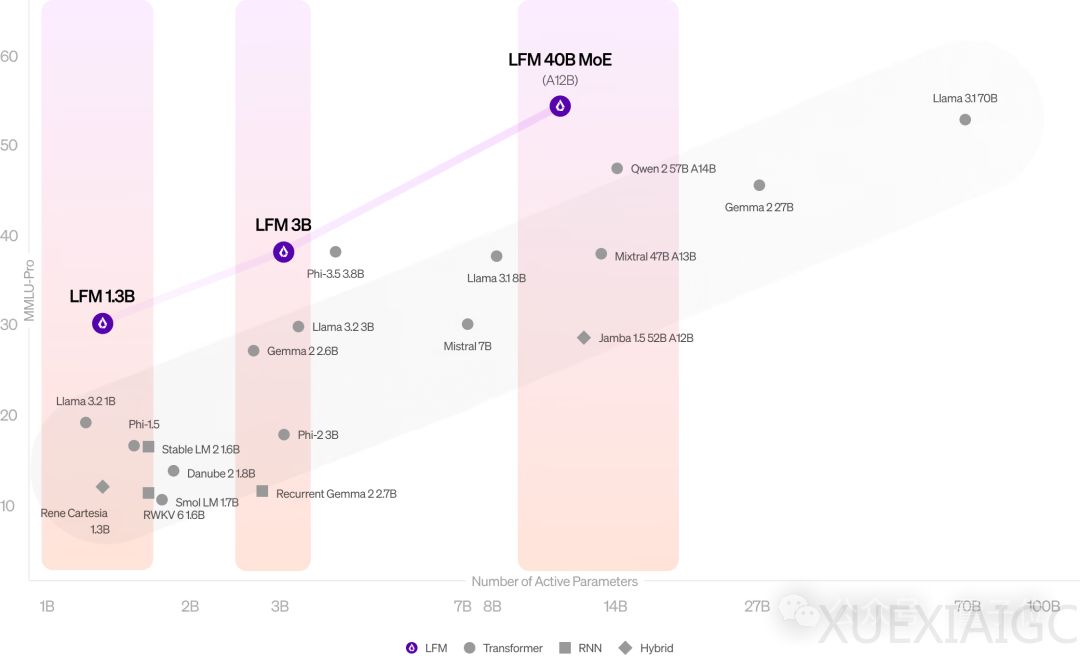
MIT初创团队Liquid AI推出了一种新型架构模型LFM(Liquid Foundation Model),在性能上超越了同等规模的Transformer模型如Llama3.2。LFM模型包含1.3B和3B两个版本,并且还有基于MoE的LFM 40B版本,该版本激活了12B参数,能够与更大规模的密集模型或MoE模型竞争。
LFM架构的核心是液态神经网络(LNN),这是一种基于第一性原理构建的计算单元,其理论基础包括动态系统理论、信号处理和数值线性代数。这种架构特别强调内存效率,与传统基于Transformer的LLM相比,LFM即使在处理100万个token时也能保持较低的内存占用,使其能够部署在移动设备上进行文档和书籍分析。
LFM模型在多个基准测试中取得了SOTA(State of the Art)性能,包括MMLU、MMLU-Pro、ARC-C、GSM8K等。LFM 3B在内存占用方面表现突出,处理100万个token时仅需16 GB内存,远低于Llama-3.2-3B模型的48 GB+。此外,LFM的有效上下文长度为32k,且在32k上下文长度上能保持89.5的高分。
LFM的另一个优势是其结构化运算符,这为模型设计提供了新的空间,使其不仅适用于语言处理,还可以应用于音频、时间序列、图像等其他模态。此外,LFM具有高适应性,可以针对特定平台或参数要求进行优化。
Liquid AI团队列出了LFM模型的优缺点,指出其擅长通用和专业知识、数学和逻辑推理、长上下文任务,但目前不擅长零样本代码任务、精确的数值计算和时效性信息。
Liquid AI团队由四位联合创始人组成,包括CEO Ramin Hasani、CTO Mathias Lechner、首席科学官Alexander Amini和MIT CSAIL主任Daniela Rus。团队致力于从第一性原理出发构建新一代基础模型,之前的研究成果丰富。
LFM模型目前处于预览测试阶段,可以通过Liquid官方平台、Lambda Chat、Perplexity AI进行访问。官方表示将持续发布技术博客以提供更多技术细节。
原文和模型
【原文链接】 阅读原文 [ 1367字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




