文章摘要
【关 键 词】 开源项目、音频驱动、视觉合成、音视频同步、高保真
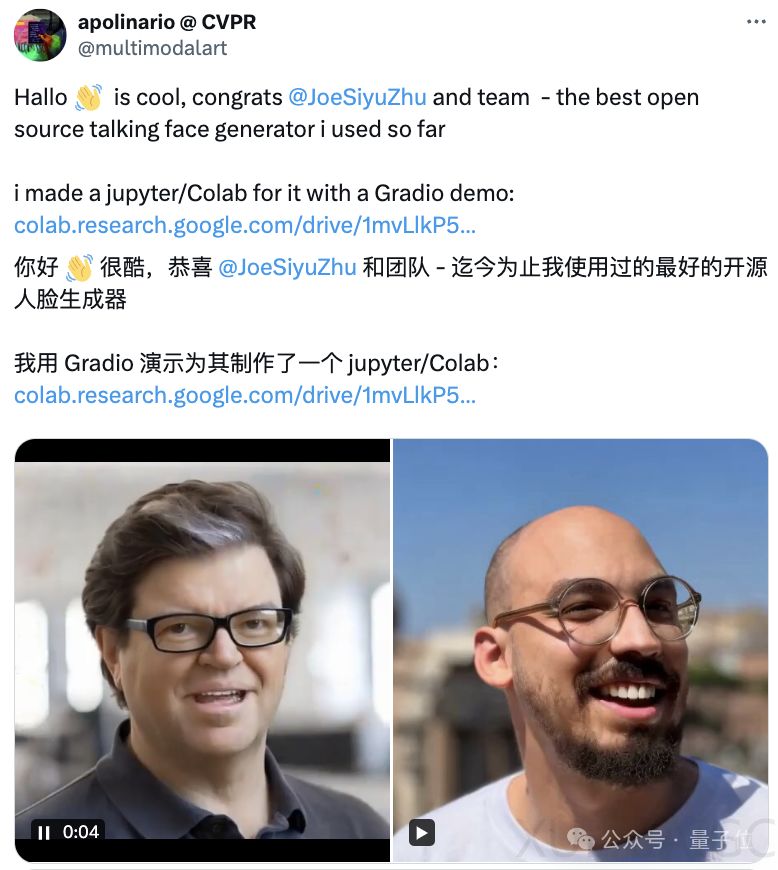
Hallo是一种基于分层音频驱动视觉合成模块的开源项目,由复旦大学、百度、苏黎世联邦理工学院和南京大学的研究人员共同完成。该项目的主要贡献是提出了一种分层的音频驱动视觉合成方法,通过将人脸划分为嘴唇、表情和姿态三个区域,分别学习它们与音频的对齐关系,再通过自适应加权将这三个注意力模块的输出融合在一起,从而更精细地建模音视频同步。
在定量评估方面,Hallo在多个指标上表现最优,包括FID、FVD、Sync-C和E-FID等。在增强唇部同步的同时,Hallo保持了高保真视觉生成和时间一致性。此外,Hallo还在CelebV数据集上展示了最低的FID和FVD以及最高Sync-C。
在定性评估方面,Hallo展示了对不同风格人像的驱动生成能力,体现了该方法的泛化和鲁棒性。例如,它可以很好地处理自建Wild数据集上的图像,并在不同的人像风格之间进行转换。
总的来说,Hallo是一种创新的音视频同步生成方法,具有很高的实用价值和研究价值。
原文和模型
【原文链接】 阅读原文 [ 3166字 | 13分钟 ]
【原文作者】 量子位
【摘要模型】 generalv3.5
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



