模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆
文章摘要
【关 键 词】 上下文窗口扩展、CEPE、长上下文、内存优化、训练成本
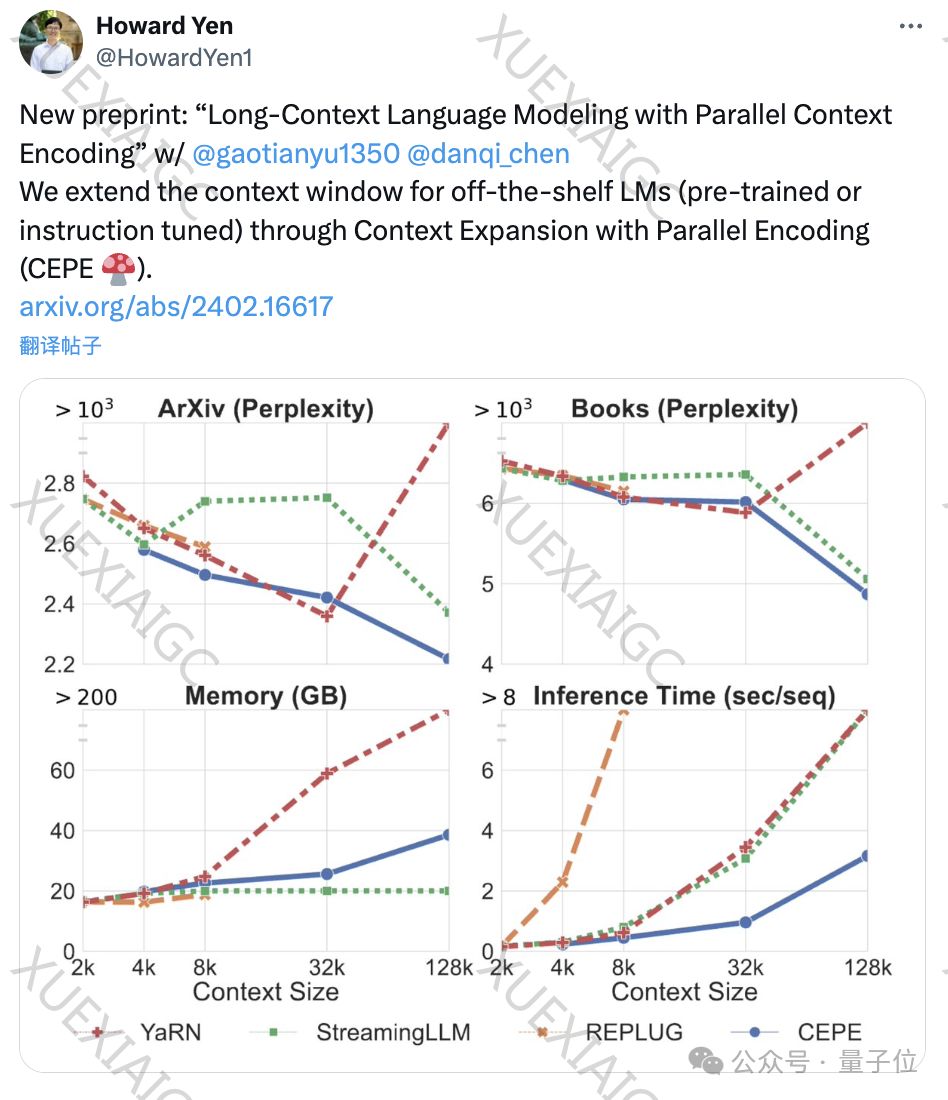
陈丹琦团队发布了一种名为CEPE(并行编码上下文扩展)的新方法,该方法通过添加小型编码器和交叉注意力模块,扩展了预训练和指令微调模型的上下文窗口。
这种方法在保持低内存使用率的同时,显著提高了模型的吞吐量,并降低了训练成本。
CEPE在多个任务上表现出色,包括降低困惑度、增强检索能力和提升开放域问答能力。
此外,团队还提出了CEPE-Distilled(CEPED),一种专门用于指令调优模型的变体,它使用未标记数据扩展上下文窗口,同时保留指令理解能力。
论文和代码已在HuggingFace和GitHub上发布。
原文信息
【原文链接】 阅读原文
【阅读预估】 1429 / 6分钟
【原文作者】 量子位
【作者简介】 追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



