文章摘要
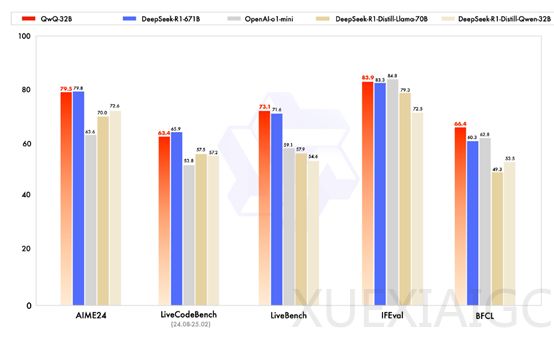
阿里巴巴近日开源了其最新的大模型QwQ-32B,该模型支持Apache 2.0开源协议,允许商业化使用。QwQ-32B在多个主流测试基准中表现优异,能够与DeepSeek的R1-671B和OpenAI的o1-mini相媲美,尽管其参数规模仅为320亿,远低于R1-671B的6710亿。这一显著的性能提升主要归功于大规模强化学习的应用,使得模型具备了深度思考和复杂推理的能力。
在数学和编程任务中,QwQ-32B通过独特的反馈机制进行训练。对于数学问题,模型不仅关注最终答案的正确性,还通过分析推理过程的每一步来提供精确的反馈。例如,在复杂的数学证明题中,若某一步推理错误,模型会收到相应的负反馈,从而改进推理过程。在编程任务中,模型生成的代码通过执行服务器进行评估,确保代码能够通过测试用例。这种反馈机制使得模型能够快速了解代码的实际运行效果,并有效改进代码生成策略。
在完成初始阶段的训练后,QwQ-32B进一步接受通用能力的强化学习训练。这一阶段使用通用奖励模型和基于规则的验证器,从更广泛的角度评估模型的行为。例如,在文本生成任务中,不仅评估生成文本的语法正确性,还评估其逻辑性和连贯性。基于规则的验证器则根据既定规则对模型输出进行验证,如在信息抽取任务中,验证抽取的信息是否符合特定格式或语义规则。通过这一阶段的训练,模型在提升通用能力的同时,数学和编程任务的性能并未显著下降,表明不同阶段的强化学习训练具有互补性和兼容性。
此外,QwQ-32B还集成了与Agent相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。例如,在智能客服系统中,Agent可以根据用户反馈调整回答策略,类似于人类客服根据用户反应调整沟通方式。阿里表示,大规模强化学习为模型性能提升带来了新的突破方向,尤其是在动态交互和策略优化方面具有显著优势。通过冷启动数据和多阶段训练,模型能够在复杂任务中逐步提升性能。同时,强化学习能够提高模型的参数利用效率,使得较小规模的模型也能达到与大规模模型相当的性能。
原文和模型
【原文链接】 阅读原文 [ 1079字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★☆☆☆☆


相关文章




