文章摘要
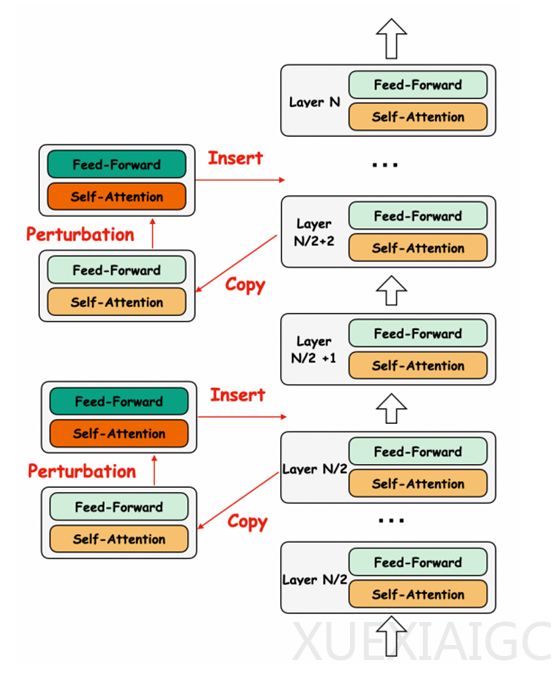
阿里巴巴开源的多语言大模型Babel,旨在解决资源匮乏语言在人工智能领域中的不足。该模型支持25种主流语言,覆盖全球90%以上的人口,包括豪萨语、波斯语、印地语等。Babel提供了9B和83B两个版本,分别针对高效推理和微调设计以及更高性能需求。Babel的创新之处在于其独特的层扩展技术,通过在模型中插入额外的层来增加参数数量,从而提升性能。这种技术在模型的后半部分插入新层,保持了模型结构的完整性,并通过复制原始参数的方法,最大程度地保留了原始模型的特征表示。
在预训练方面,Babel采用了两阶段策略。第一阶段是恢复阶段,使用大规模多样化语料库进行训练,以恢复模型在扩展过程中可能损失的性能。第二阶段是持续训练阶段,重点提升模型的多语言能力,特别是低资源语言。通过增加低资源语言的比例和提高教材在训练语料库中的占比,Babel增强了对低资源语言的支持,并提升了在多语言任务中的整体表现。
为了验证Babel模型的性能,研究人员在多个主流基准测试中进行了评估。结果显示,Babel-9B在所有基准测试中的平均得分为63.4,超过了其他竞争对手,如Gemma2-9B和Qwen2.5-7B。尤其是在XCOPA、MGSM、XNLI和Flores-200等任务中,Babel-9B均取得了最高分,显示出在多语言推理、理解和翻译方面的强大能力。Babel的层扩展技术和两阶段预训练策略,不仅提升了模型的性能,还增强了对低资源语言的支持,为多语言人工智能领域的发展提供了新的可能性。
原文和模型
【原文链接】 阅读原文 [ 1205字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



