文章摘要
【关 键 词】 视频生成、运动控制、轨迹可控、技术创新、AIGC应用
视频生成技术在近年来取得了显著进展,特别是在运动控制方面。阿里云提出的基于Diffusion Transformer (DiT) 架构的轨迹可控视频生成模型Tora,通过其创新架构和训练策略,实现了在720p分辨率下长达204帧的稳定运动视频生成。Tora模型不仅继承了DiT的scaling特性,生成的运动模式也更流畅且符合物理世界规律。
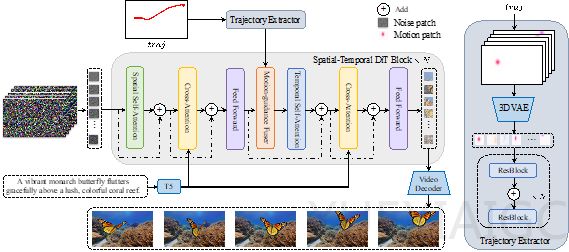
Tora模型由三个主要部分组成:Spatial-Temporal Denoising Diffusion Transformer (ST-DiT)、Trajectory Extractor (TE) 和 Motion-guidance Fuser (MGF)。ST-DiT通过时空视觉补丁的压缩和变换器块进行噪声预测,而TE和MGF则负责将用户提供的轨迹编码为时空运动补丁,并整合到DiT块中,确保生成视频的运动与预定义轨迹一致。
在轨迹提取方面,Tora采用了3D motion VAE将轨迹向量嵌入到潜在空间中,并通过高斯滤波减轻发散问题。MGF则通过自适应归一化层动态调整特征,以维持视频运动的连续性和自然性。
Tora的训练采用了改进的数据处理流程,结合运动分割结果和光流分数,提高了对前景物体轨迹的跟随准确率。训练视频来源于互联网高质量视频数据和公司内部数据,支持任意数量的视觉条件引导。
在对比实验中,Tora在不同帧数设置下均展现出了优越的性能,尤其是在128帧测试下,轨迹准确度比其他方法高出3至5倍。此外,Tora在更长时间内保持了有效的轨迹控制,表现出逐渐的误差增加。
Tora模型的提出,为视频生成技术的发展提供了新的思路和方法,有望推动AIGC领域的进一步发展和应用落地。
原文和模型
【原文链接】 阅读原文 [ 2655字 | 11分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章



