通用文档理解新SOTA,多模态大模型TextMonkey来了
文章摘要
【关 键 词】 TextMonkey、多模态、视觉问答、文档VQA、技术变革
华中科技大学和金山的研究人员在多模态大模型Monkey的基础上提出了TextMonkey,这是一个专注于文本相关任务的多模态大模型。TextMonkey在多个场景文本和文档的测试基准中处于国际领先地位,有潜力带来办公自动化、智慧教育、智慧金融等行业应用领域的技术变革。
TextMonkey相较于Monkey在多个方面进行了改进。首先,通过采用零初始化的Shifted Window Attention,TextMonkey实现了更高输入分辨率下的窗口间信息交互。其次,通过使用相似性过滤出重要的图像特征,TextMonkey能够简化输入并提高模型性能。此外,TextMonkey通过扩展多个文本相关任务并将位置信息纳入回答,增强了可解释性并减少了幻觉。微调后的TextMonkey还具备APP Agent中理解用户指令并点击相应位置的能力,展现了其下游应用的巨大潜力。
TextMonkey的核心在于模拟人类视觉认知的方法,使其能够识别高清文档图像中各部分的相互关联,并灵敏地鉴别图像内的关键要素。TextMonkey通过文本定位技术强化了答案的准确性,提升了模型的解释性,减少了幻觉,有效提高了处理各类文档任务上的表现。
TextMonkey采用了Shifted Window Attention、Token Resampler和多任务训练等方法。Shifted Window Attention通过滑动窗口注意力机制建立块与块之间的上下文联系,解决了图像切分为小块带来的问题。Token Resampler通过计算图像token的相似度,过滤得到最重要的K个token,进一步融合所有特征。多任务训练使TextMonkey支持多个文本相关任务,增强了模型的可解释性。
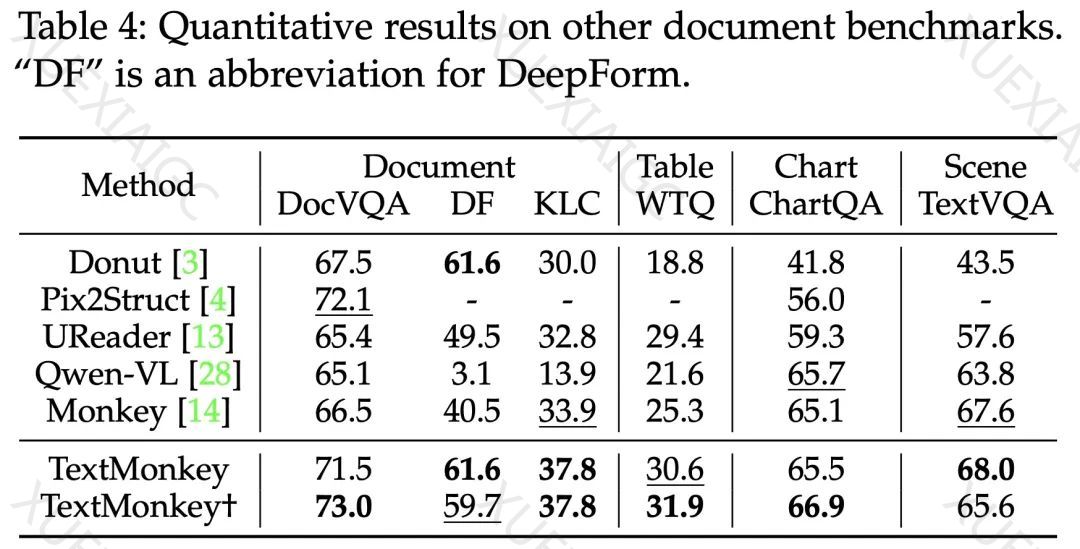
实验结果表明,TextMonkey在各种基准数据集上的性能得到了显著提升。在场景文本为中心的视觉问答、文档VQA和关键信息抽取任务中分别取得了5.2%、6.9%和2.8%的准确率增长。特别是在OCRBench上获得了561的得分,超越了此前所有已开源的多模态大模型。
TextMonkey在场景图像和文档图像中都能准确定位和识别文本。此外,它在多种场景下展示了识别、理解和定位文本信息的能力。在智能手机应用程序的Agent代理方面,TextMonkey在Rico数据集上进行微调后,能够理解用户意图并点击相应的图标,表明了其作为App Agent的巨大潜力。
总结来说,TextMonkey在Monkey的基础上增强了图像间的跨窗口交互,有效缓解了视觉信息碎片化问题。通过提出过滤融合策略减少图像特征长度,减少了输入到大语言模型中冗余的视觉token数量。实验表明,分辨率不是越大越好,不合理的提高模型分辨率策略有时会给模型带来负面影响。TextMonkey在多个文本相关的测试基准中处于国际领先,为通用文档理解带来曙光,有潜力促进办公自动化、智慧教育、智慧金融等行业的技术变革。
原文和模型
【原文链接】 阅读原文 [ 2242字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




