文章摘要
【关 键 词】 注意力技术、无限注意力、压缩记忆系统、长上下文语言建模、多模态领域
本文介绍了谷歌发布的一篇论文《Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention》,该论文提出了一种新的注意力技术——“无限注意力”(Infini-attention)。这项技术使得transformer大模型能够在有限的计算资源下处理无限长度的输入。
在传统的transformer模型中,注意力机制通过上下文窗口限制了模型在计算注意力时考虑的元素范围。而无限注意力技术允许模型在处理无限长输入序列时,不需要丢弃前一输入段的注意力状态,从而实现无限的上下文窗口。
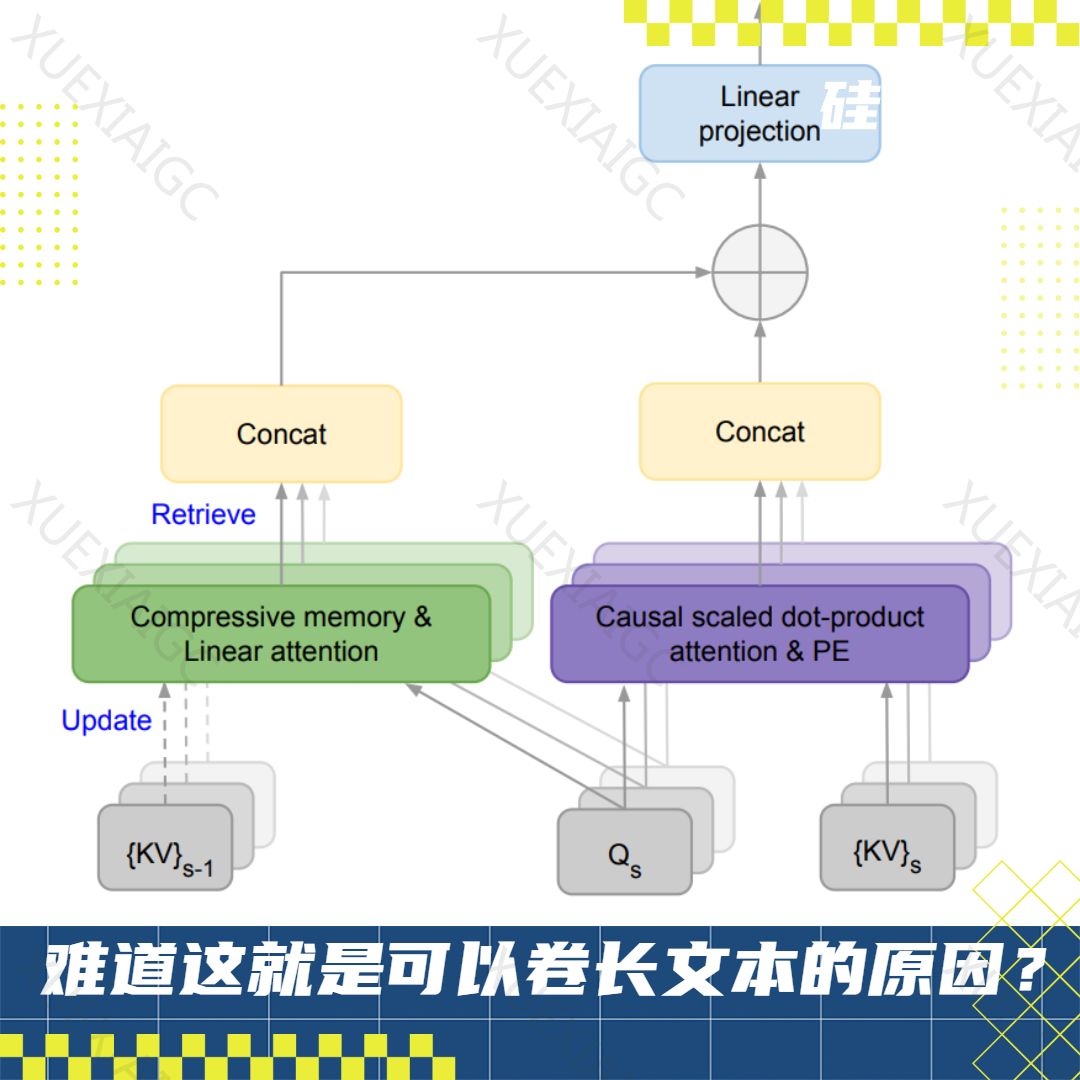
无限注意力机制的核心是压缩记忆系统,这是一种能够紧凑地存储和检索大量信息的结构。它通过改变参数来捕获新信息,并确保信息可以在之后被恢复。这种系统解决了标准注意力机制在处理长序列时内存和计算时间的二次复杂度问题,因为其参数数量不随输入序列长度变化,从而保持模型复杂度不变。
无限注意力模型将输入序列分为一系列固定长度的子序列,以降低内存需求和计算复杂度。模型以流式方式逐步处理输入,每次仅处理一个或几个段。在每个分段内部,模型采用局部注意力机制来处理段内上下文信息,通常采用因果或自回归的形式,确保模型在处理当前token时,只能看到该token之前的所有token。
在输出结果时,无限注意力模型将压缩记忆中的长期记忆信息与当前局部注意力计算出的上下文结合起来,生成最终的上下文输出。这种融合确保模型既考虑了当前输入段的局部依赖,又利用了历史输入的长期上下文。
论文评估了无限注意力模型在长上下文语言建模基准上的表现,并与其他模型进行了对比。结果显示,无限注意力模型在PG19和Arxiv-math数据集上均取得了优于transformer-XL的结果,并实现了显著的内存压缩率。
为了进一步验证无限注意力机制的性能,论文对一个10亿参数的大语言模型进行了改造,并对其进行了预训练和微调。实验结果表明,无限注意力模型能够在不同长度和不同密钥位置的长输入文本中成功检索隐藏的密钥。此外,团队还对一个80亿参数的大语言模型进行了预训练,并在BookSum数据集上进行了微调,模型在生成摘要任务上实现了新的SOTA性能。
文章最后指出,无限注意力和之前deepmind提出的∞-former模型在方法上有相似之处,但无限注意力在精准度上有显著提高。这些技术都是对transformer记忆系统的改进,但transformer无法处理非连续数据,这限制了其在多模态领域的应用。谷歌可能会开始研究数据结构方面的工作,以扩大其在多模态领域的领先地位。
原文和模型
【原文链接】 阅读原文 [ 2019字 | 9分钟 ]
【原文作者】 硅星人Pro
【摘要模型】 gpt-4
【摘要评分】 ★★★★★


相关文章




