文章摘要
【关 键 词】 强化学习、游戏AI、世界模型、深度强化学习、AGI
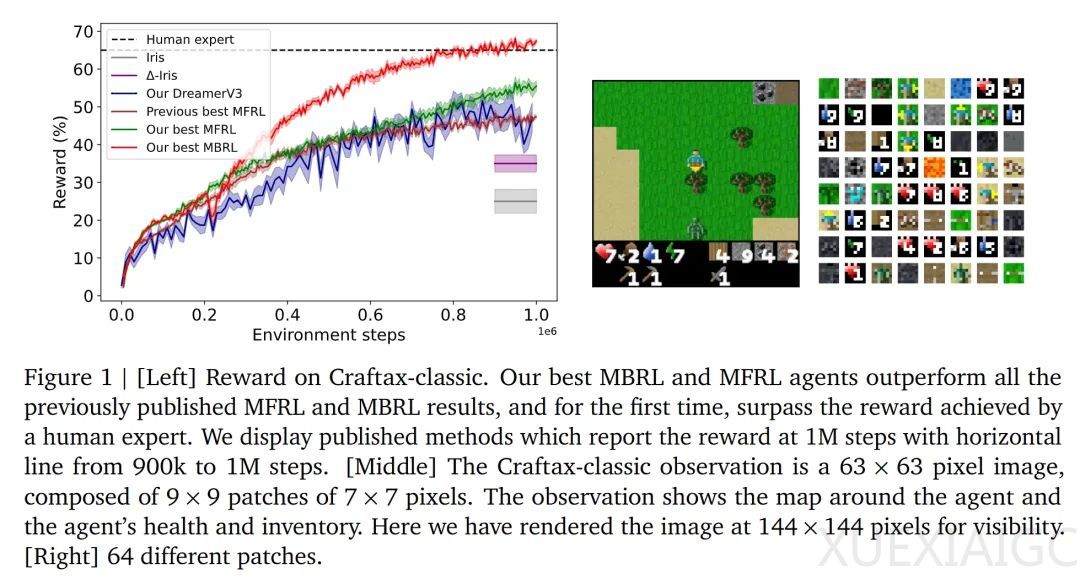
DeepMind研究团队通过改进基于Transformer世界模型的强化学习技术,在Craftax-classic游戏中实现了AI智能体对人类的超越。该智能体仅需100万步环境交互即可获得67.42%的奖励和27.91%的得分,显著优于此前53.20%奖励和19.4%得分的SOTA水平。研究从模型架构、数据利用方式和训练方法三个维度进行创新,提出融合真实与虚拟数据的Dyna算法、图像块最近邻标记器(NNT)及块状教师强制(BTF)三项关键技术。
在模型架构方面,研究团队发现结合适当规模的Transformer模型与GRU记忆模块能有效提升性能,相比基线模型的46.91%奖励,改进后达到55.49%。通过控制隐藏状态维度,确保记忆系统仅聚焦于当前图像无法捕获的关键历史信息。这种设计在A100 GPU上仅需15分钟即可完成100万步训练,显著降低计算成本。
数据利用方式的创新体现在Dyna算法的改进应用。将真实环境数据与世界模型生成的虚拟数据按1:1比例混合训练,配合预热机制确保模型准确性,使得奖励指标从43.36%提升至67.42%。实验表明,若取消预热阶段直接使用虚拟数据,性能会骤降至33.54%。这种混合训练机制有效平衡了数据效率与模型可靠性,避免错误预测对策略学习的干扰。
图像处理技术的突破来自NNT标记器的研发。通过将63×63像素画面分解为9×9个7×7图像块,采用静态代码本进行最近邻编码,替代传统VQ-VAE方法,使奖励从58.92%跃升至64.96%。该方法利用Craftax-classic环境的结构特性,通过固定但可扩展的代码本简化模型学习过程,同时保持对画面局部特征的敏感性。
训练方法的革新体现在块状教师强制(BTF)的提出。通过并行预测同时间步所有潜在token,替代传统自回归方式,将模型准确率提升至67.42%,最终实现超越人类专家水平。比较实验显示,BTF生成的轨迹在符号准确率指标上较基线模型提升38%,且在视觉评估中展现出更符合游戏规则的环境动态模拟能力。
研究团队将该方法扩展到更复杂的Craftax完整版环境测试,MBRL智能体以5.44%的奖励刷新SOTA纪录,较之前最佳结果提升136%。消融实验证实,图像块尺寸优化、模型规模控制与RNN记忆模块的协同设计对性能提升具有决定性作用。未来工作将探索预训练模型融合与优先经验回放技术,以提升方法的泛化能力和数据利用效率。
原文和模型
【原文链接】 阅读原文 [ 4372字 | 18分钟 ]
【原文作者】 新智元
【摘要模型】 deepseek/deepseek-r1/community
【摘要评分】 ★★★★★


相关文章




