文章摘要
【关 键 词】 字节跳动、Doubao-Coder、AI编程、FullStack Bench、代码沙盒
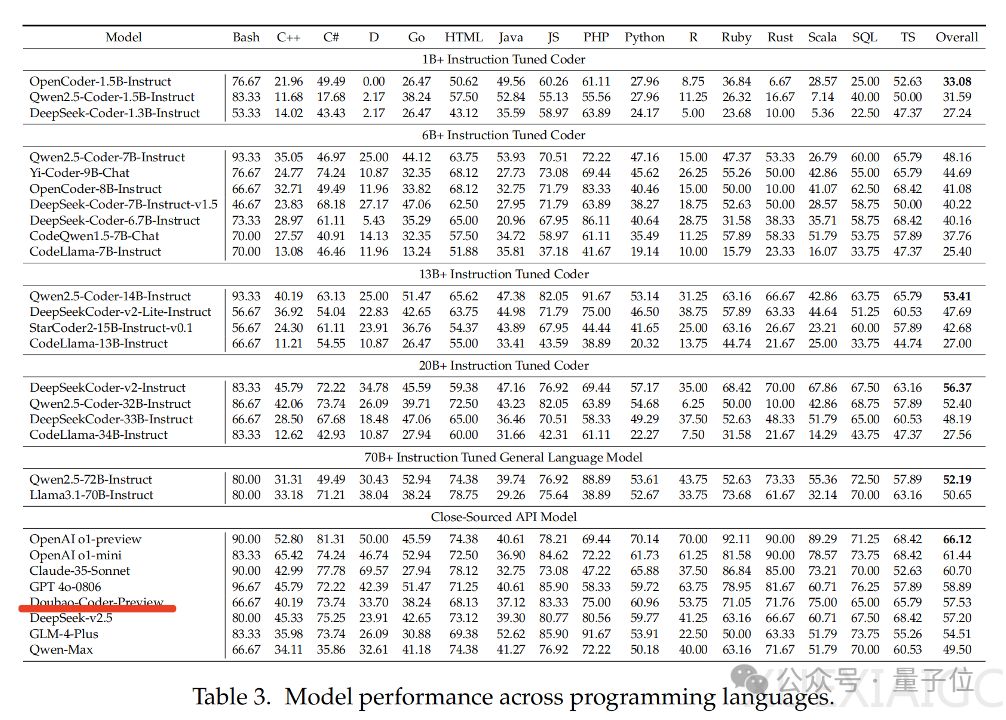
字节跳动在其开源的代码大模型评估基准FullStack Bench中意外曝光了尚未公开的Doubao-Coder模型。尽管Doubao-Coder目前仅处于预览版阶段,但已在闭源模型中排名第五。字节跳动今年6月发布的AI编程助手豆包MarsCode据称由Doubao-Coder模型支持,每月为用户贡献百万量级代码。
FullStack Bench是一个全面的代码评估数据集,由字节跳动的豆包大模型团队与M-A-P社区联合开源,专注于全栈编程和多语言编程。该数据集覆盖了超过11类真实场景和16种编程语言,包含3374个问题,应用领域源自Stack Overflow,覆盖的编程领域是其他基准的一倍以上。
FullStack Bench包含3374个问题,每个问题都包括题目描述、参考解决方案、单元测试用例及标签,总计15168个单元测试。问题内容由编程专家设计,并经过AI和人工验证。团队还根据主流代码大模型测试结果对数据质量进行了交叉评估和完善。
为了系统性测试大模型代码能力,豆包大模型团队开源了代码沙盒执行工具SandboxFusion,兼容超过10种代码评估数据集,支持23种编程语言。开发者可以在单服务器上部署SandboxFusion,也可以在GitHub上体验。
研究团队基于FullStack Bench测评了全球20余款代码大模型的编程表现。跨领域表现中,数学编程领域差异最大,OpenAI o1-preview领先,但一些开源模型也有不错表现。跨语言表现中,C++、C和Ruby上存在较大差异。解决难题时,闭源模型普遍优于开源模型。使用SandboxFusion可以提升模型表现,”反思策略”明显优于”N次推断策略”。
原文和模型
【原文链接】 阅读原文 [ 2010字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章




