谷歌DeepMind:大模型也很任性,知道最优路径偏要撞南墙
文章摘要
【关 键 词】 大模型、决策缺陷、强化学习、频率偏差、知-行差距
大语言模型(LLMs)在智能体应用中的潜力引发了广泛关注,但其在决策场景中的表现却存在显著缺陷。谷歌DeepMind的研究者深入分析了LLMs在决策中的三种常见失败模式:贪婪性、频率偏差和知-行差距。这些缺陷导致模型在探索和行动转化方面表现不佳,限制了其解决复杂问题的能力。
贪婪性是LLMs最普遍的失败模式,表现为模型过早地倾向于选择已知的少数最优动作,导致动作覆盖率停滞。实验显示,即使在多臂老虎机(MAB)环境中,模型的覆盖率在10步后便停止增长,最大模型仅覆盖了45%的动作。这种贪婪行为显著降低了模型的性能,使其与最优策略相比存在较高的遗憾值。
频率偏差是另一个关键问题,尤其是对于小规模模型(如2B)。这些模型倾向于重复选择上下文中出现频率最高的动作,即使该动作的奖励较低。随着重复次数的增加,模型的熵值不断降低,表明其探索能力受限。尽管大规模模型(如27B)能够显著减弱频率偏差,但仍受到贪婪行为的影响。
知-行差距则揭示了LLMs在知识与行动之间的脱节。尽管模型能够正确理解任务要求并生成87%的正确推理,但在实际决策中,58%的情况下仍会选择贪婪动作而非最优动作。这种差距表明,LLMs在将知识转化为有效行动方面存在显著不足。
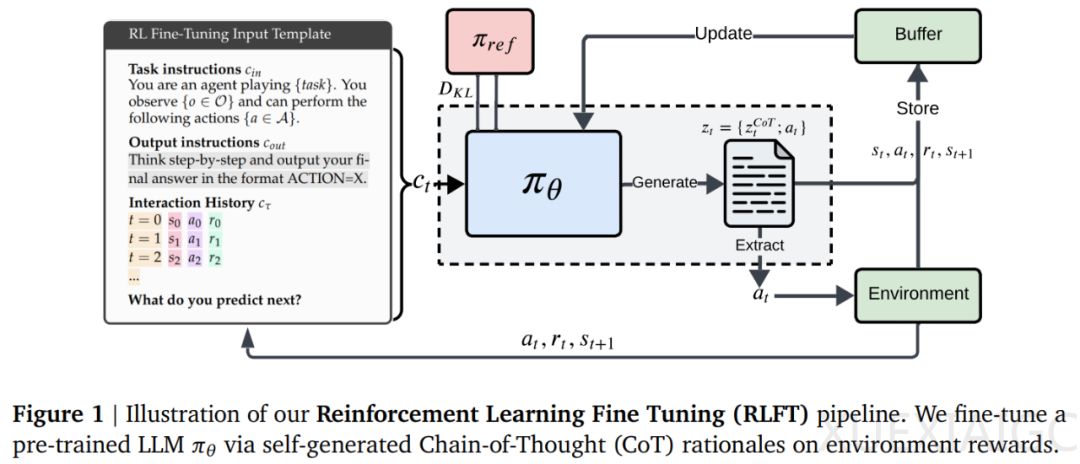
为缓解这些缺陷,研究者提出了一种基于强化学习的微调方法(RLFT)。该方法通过对自动生成的思维链(CoT)推理进行微调,使模型能够从环境交互中学习并优化其决策过程。实验结果表明,RLFT显著降低了模型的遗憾值,并缓解了贪婪性和频率偏差。特别是在小规模模型中,RLFT显著提升了探索能力,缩小了知-行差距。
总体而言,这项研究揭示了LLMs在决策场景中的核心缺陷,并提出了一种有效的改进方法。通过强化学习微调,LLMs在探索和行动转化方面的能力得到了显著提升,为其在复杂任务中的应用提供了新的可能性。
原文和模型
【原文链接】 阅读原文 [ 1439字 | 6分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




