文章摘要
【关 键 词】 自我纠错、多轮强化、大模型、SCoRe、准确率提升
在AIGC领域,大语言模型(LLM)的自我纠错能力一直是研究的重点。谷歌DeepMind的研究人员开发了一种名为SCoRe的多轮强化学习方法,旨在提升大模型在数学和代码领域的准确率和自我纠错能力。这种方法通过避免训练数据与模型实际响应分布不匹配的问题,并引入多轮反馈奖励机制,帮助模型及时纠正错误。
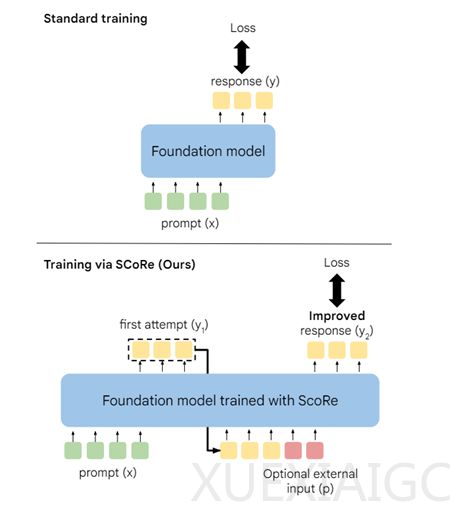
传统的大模型训练依赖于监督学习,但这种方法存在数据分布差异的问题,导致模型在实际应用中难以自我纠错。例如,在图像识别任务中,模型可能无法识别与训练数据差异较大的图像。SCoRe通过在模型自己生成的数据上进行多轮强化训练,使模型能够根据奖励信号调整输出,实现自我纠正。
SCoRe的强化学习方法分为两个阶段。第一阶段是对基础模型进行初始化训练,目标是产生高质量的回答,并在第二次尝试时进行有效纠正。这一阶段通过计算模型输出与基础模型输出之间的KL散度来施加正则化约束,鼓励模型在第二次尝试中进行更大胆的纠正。
第二阶段是多轮强化学习与奖励塑造。在这一阶段,模型在每一轮尝试中都会接收到基于当前尝试与正确答案匹配程度的奖励信号。模型通过最大化这些奖励信号来逐步学习改进答案。研究人员还为模型在第二次尝试中正确纠正错误的行为提供了额外的奖励,以引导模型学习有效的自我纠正能力。
研究人员在谷歌自研的Gemini 1.0 Pro和Gemini 1.5 Flash两款大模型上进行了数学和代码测试,验证了SCoRe的性能。结果显示,SCoRe显著提升了模型的自我纠正能力,分别提升了15.6%和9.1%。这表明SCoRe是一种有效的多轮强化学习方法,能够显著提升大模型的自我纠错能力和准确率。
原文和模型
【原文链接】 阅读原文 [ 1293字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章



