谷歌具身智能新研究:比RT-2优秀的RT-H来了
模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 DeepMind、RT-H、VLA、行动层级、语言动作
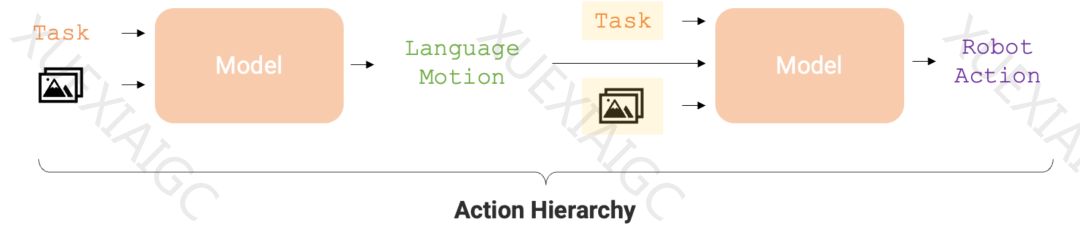
谷歌DeepMind的RT系列机器人在具身智能研究中取得了显著进展。RT-2是全球首个控制机器人的视觉-语言-动作(VLA)模型,能够通过对话识别图像并执行任务。现在,RT-H作为RT-2的升级版,通过将复杂任务分解为简单的语言指令,提高了任务执行的准确性和学习效率。RT-H利用视觉语言模型(VLM)预测语言动作,然后根据这些动作预测机器人的具体行动。这种行动层级(action hierarchy)使得RT-H在多项机器人任务中的表现优于RT-2。
RT-H的研究论文《RT-H: Action Hierarchies Using Language》详细介绍了这一模型。论文指出,语言是人类推理的引擎,它使我们能够将复杂概念分解为简单组成部分,并在新环境中推广概念。机器人也开始利用语言的结构来分解高层次概念、提供语言修正或实现在新环境下的泛化。RT-H通过分析观察结果和高层次任务描述来预测当前的语言动作指令,然后预测相应的行动。此外,研究者还开发了一种自动化方法,从机器人的本体感受中提取简化的语言动作集,建立了包含超过2500个语言动作的数据库。
RT-H的模型架构借鉴了RT-2,采用单一模型同时处理语言动作和行动查询,充分利用互联网规模知识。在实验中,RT-H在处理多样化的多任务数据集时表现出显著的改善,相比RT-2在一系列任务上的表现提高了15%。研究还发现,对语言动作进行修正能够达到接近完美的成功率,展示了学习到的语言动作的灵活性和情境适应性。RT-H在泛化性能上也优于RT-2,更好地适应场景和物体变化。
研究团队通过四个关键实验问题全面评估了RT-H的性能,包括性能、情境性、纠正和概括。实验结果表明,带有语言的行动层级可以提高多任务数据集上的策略性能,RT-H学得的语言动作与任务和场景情境相关,语言动作修正有助于提高任务成功率,行动层级可以提高分布外设置的稳健性。这些发现为机器人学习和执行复杂任务提供了新的视角和方法。
原文信息
【原文链接】 阅读原文
【阅读预估】 3098 / 13分钟
【原文作者】 机器之心
【作者简介】 专业的人工智能媒体和产业服务平台

相关文章





