训练1000样本就能超越o1,李飞飞等人画出AI扩展新曲线
文章摘要
【关 键 词】 AI推理、测试时间扩展、样本效率、开源模型、竞赛数学
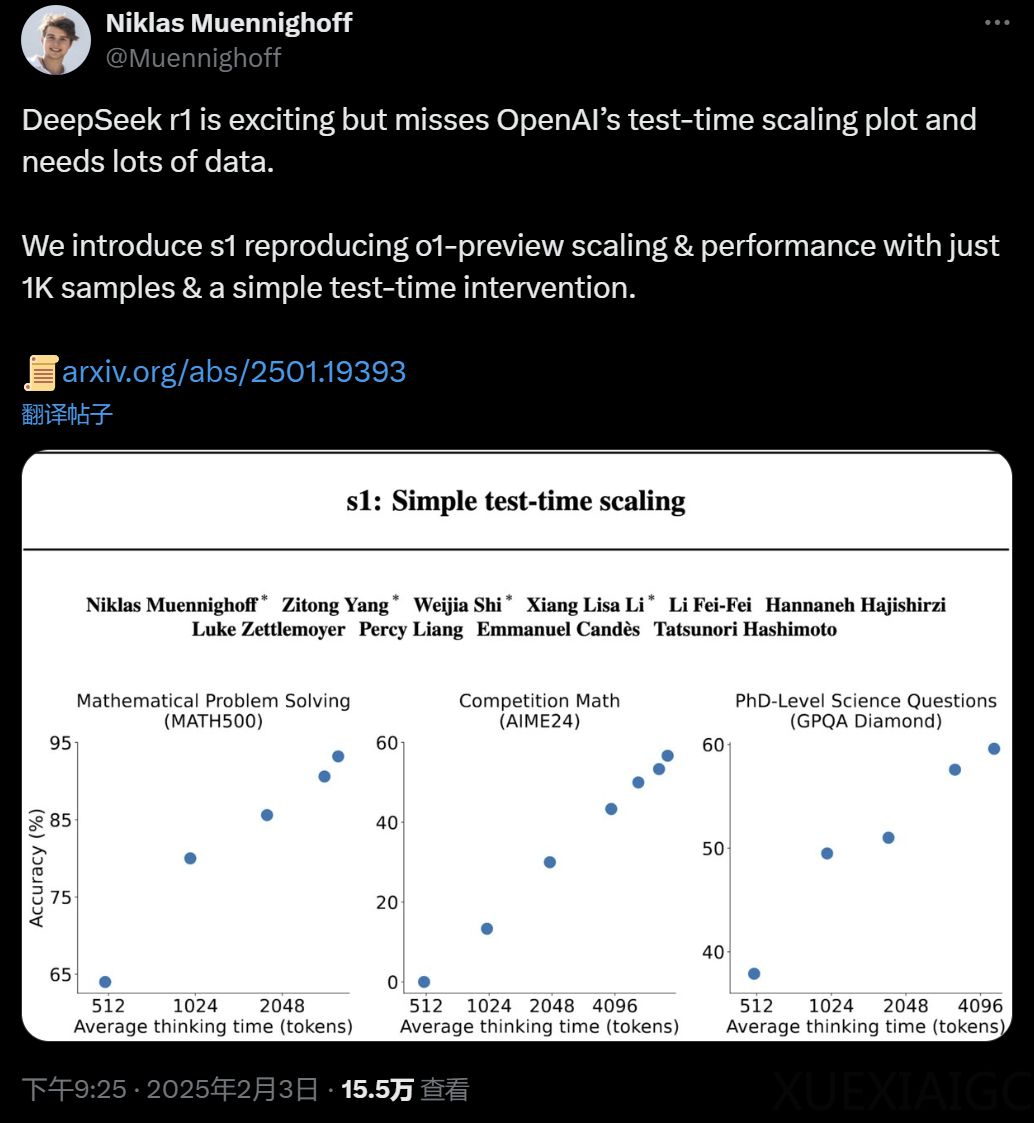
斯坦福大学在读博士Niklas Muennighoff领导的研究团队提出了一种名为s1的新方法,旨在改进AI的推理效率。s1方法通过仅使用1000个样本和简单的测试时间干预,成功复现了OpenAI的o1模型的预览扩展和性能。这种方法被称为测试时间扩展,它通过额外的测试时间计算来提高模型性能。s1通过构建小型数据集s1K,并采用“预算强制”策略控制测试时间计算,实现了对模型思考过程的强制终止或延长,以提高推理性能。
在s1K数据集上对Qwen2.5-32B-Instruct语言模型进行监督微调后,新模型s1-32B在竞赛数学问题上的表现比o1-preview高出27%。s1-32B是完全开源的,包括权重、推理数据和代码。研究团队将s1-32B与OpenAI o1、DeepSeek r1等模型进行对比,发现s1-32B在样本效率上表现最佳,尽管只在额外的1000个样本上进行训练,但表现明显优于基础模型。
s1-32B在AIME24上几乎与Gemini 2.0 Thinking相匹配,这表明研究团队的蒸馏程序可能是有效的。此外,s1-32B在测试时间扩展方面表现出色,随着测试时间计算资源的增加,性能得到提升,但在六倍计算量时趋于平缓。研究还提出了新的序列扩展方法和基准测试方式,为测试时间扩展领域提供了新的视角和方法。
这项研究展示了通过简化的方法实现测试时间扩展的潜力,为提高AI推理效率提供了新的思路。s1-32B的开源特性也有助于推动相关领域的研究和应用。
原文和模型
【原文链接】 阅读原文 [ 1843字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



