文章摘要
【关 键 词】 大模型微调、主动学习、数据筛选、模型评估、数据用量
大模型应用于特定领域需数据微调,但为复杂任务微调大模型时,筛选高保真训练数据难度大、成本高。为此,谷歌提出新的可扩展主动学习筛选流程。
该流程从初始模型(LLM – 0)开始,为其提供描述目标内容的提示,生成大型标记数据集。初始数据集通常高度不平衡,且初始模型准确识别能力弱。通过将模型标记的不同类别内容分组,找出重叠组中内容相似但标签相反的样本对交给专家判断,优先选择能覆盖更多不同情况的样本对,这些样本既具价值又是模型易混淆的边界案例。
专家标注随机分为两组,一组用于模型评估,采用内部一致性和模型 – 人类一致性两个关键指标;另一组用于微调当前模型,重复迭代,直至模型 – 人类一致性与内部一致性匹配或达到平台期。由于广告安全领域分类问题本质模糊,不依赖精确率和召回率等需真值标签的标准指标,而是使用科恩 kappa 系数评估。
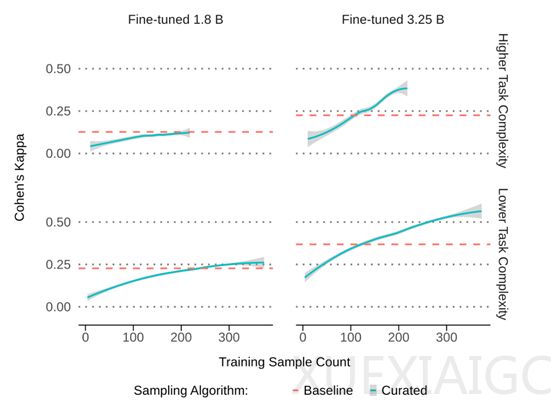
为验证方法有效性,谷歌用 Gemini Nano – 1 和 Nano – 2 两个模型针对不同复杂度任务进行实验。实验结果显示,专家自身判断一致性高,众包标签与专家判断一致性一般。在模型表现上,18 亿参数模型使用新方法前后效果差异不大,而 32.5 亿参数模型使用新方法后效果显著提升,仅用 250 – 450 条数据,相比原来 10 万条减少 1000 倍,一致性提高 55% – 65%。
总体而言,只要选取少量高质量数据,且专家标注一致性超过 0.8,大模型就能用极少数据达到甚至超过原来使用海量数据的效果,最多可减少 10000 倍的数据用量,但持续保持高标注质量仍面临挑战。
原文和模型
【原文链接】 阅读原文 [ 1230字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★☆☆


相关文章




