视频生成模型变身智能体:斯坦福Percy Liang等提出VideoAgent,竟能自我优化
文章摘要
【关 键 词】 视频技术、AI反馈、自我提升、视频生成、物理逻辑
当前,文本生视频技术正处于快速发展阶段,其应用范围广泛,包括创意视频内容生成、游戏场景创建、动画和电影制作,甚至作为真实世界的模拟器。尽管如此,该技术在现实世界的应用仍然受限,主要挑战包括视频内容的幻觉问题和不符合物理机制的问题。理论上,通过扩大数据集和模型规模可以缓解这些问题,但由于视频标注和整理的成本高昂,以及缺乏适合大规模扩展的架构,实际操作中存在困难。
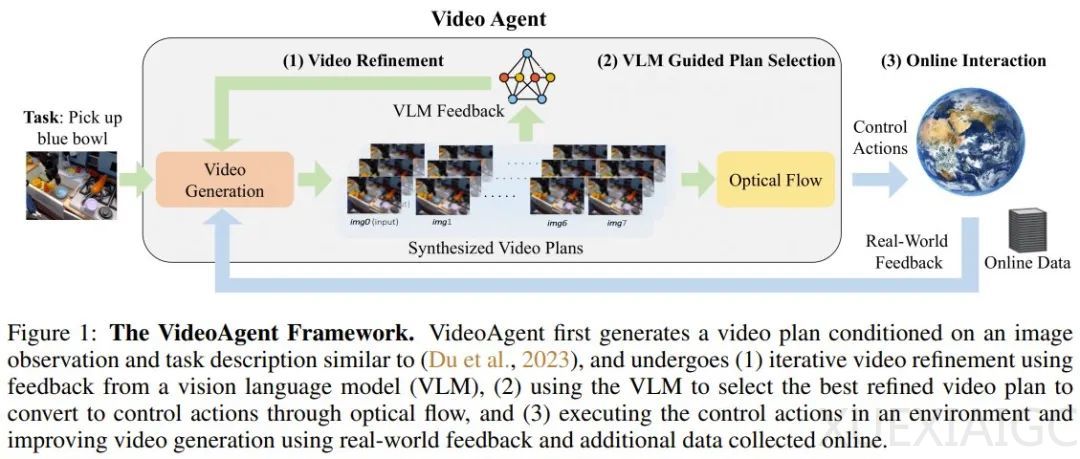
为了解决这些问题,一个多机构研究团队提出了VideoAgent,这是一种视频智能体,能够利用来自视觉-语言模型(VLM)的AI反馈和真实世界执行反馈来自我提升。VideoAgent的训练目标是使用预训练VLM的反馈来迭代优化视频规划。在推理阶段,它会查询VLM以选择最佳的改进视频规划,并在环境中执行。在线执行过程中,它会根据环境的执行反馈和收集的其他数据进一步改进视频生成模型。
该研究团队还提出了自我调节一致性的概念,用于优化视频扩散模型,将低质量样本转化为高质量样本。此外,当环境可在线访问时,VideoAgent会执行当前视频策略并收集其他成功轨迹,以微调视频生成模型。
实验评估了VideoAgent在多个数据集上的表现,包括Meta-World、iTHOR和BridgeData V2。结果显示,自我调节一致性显著提高了任务成功率,例如在关闭水龙头任务上的成功率从12%提高到46.7%。引入在线微调进一步提高了成功率,多迭代一次都能带来提升。在iTHOR数据集上,VideoAgent同样优于基线。
研究还分析了VideoAgent不同组件的效果,包括提供不同类型的反馈、改变优化和在线迭代的次数、调整VLM反馈的质量。结果表明,无论是二元反馈还是描述性反馈,都比没有反馈好,且VLM的准确性受到部分可观测性的影响。
最后,研究评估了VideoAgent在真实视频上自我优化的能力,发现其在多个指标上表现更优,能够生成更流畅、更符合现实世界物理逻辑的视频。定性评估结果也显示,VideoAgent能够很好地完成视频生成任务,而基线则出现了幻觉问题。
原文和模型
【原文链接】 阅读原文 [ 2421字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




