文章摘要
苹果公司的研究团队最近发布了一款名为AIMv2的通用多模态视觉模型,该模型具有300M、600M、1.2B和2.7B四种参数规模,并且整体能耗低,使其能够适应手机、PC等多种设备。AIMv2采用了一种创新的多模态自回归预训练方法,将视觉与文本信息深度融合,为视觉模型领域带来了新的技术突破。这种预训练方法不再局限于仅处理视觉信息的传统模式,而是将图像和文本整合为统一的序列进行预训练,其中图像被划分为不重叠的Patches形成图像token序列,文本则分解为子词令牌序列,然后将两者拼接在一起,实现了视觉与文本信息的交互融合。
AIMv2的技术架构在预训练模型中独树一帜,其多模态自回归预训练框架将图像和文本整合到一个统一的序列中,使得模型能够自回归地预测序列中的下一个标记,无论它属于哪种模态。这种框架使得AIMv2易于实现和训练,不需要非常大的批量大小或特殊的跨批次通信方法,同时与LLM驱动的多模态应用非常吻合,可以实现无缝集成。AIMv2从每个图像块和文本标记中提取训练信号,提供了比判别目标更密集的监督。
在预训练目标方面,AIMv2定义了图像和文本领域的单独损失函数,旨在平衡模型在图像和文本两个领域的性能,同时鼓励模型学习到能够准确预测两个模态的表示。预训练过程涉及到大量的图像和文本配对数据集,包括公开的DFN-2B和COYO数据集,以及苹果公司的专有数据集HQITP,为AIMv2提供了丰富的预训练数据。
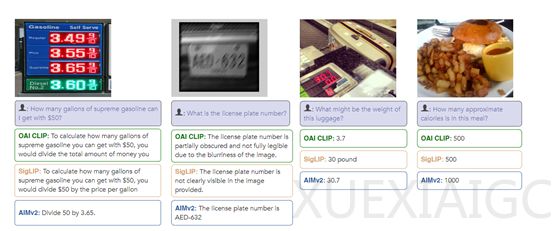
在性能测试方面,AIMv2在多个领域展现出了卓越的性能。在图像识别方面,AIMv2在ImageNet-1k数据集上达到了89.5%的准确率,这还是在冻结模型主干的情况下完成的。与其他视觉语言预训练基线模型相比,AIMv2展现出了高度竞争的性能。值得注意的是,AIMv2在训练数据量仅为DFN-CLIP和SigLIP的四分之一(12B vs. 40B)的情况下,仍能取得如此优异的成绩,且训练过程更加简便、易于扩展。此外,AIMv2在开放词汇对象检测和指代表达理解等任务上也表现出色,显示出其在多模态任务中的广泛适用性。
原文和模型
【原文链接】 阅读原文 [ 1347字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章




