文章摘要
【关 键 词】 深度学习、非凸优化、AdEMAMix、动量估计、性能提升
在深度学习模型训练中,优化非凸损失函数是一个挑战,尤其是当使用依赖于指数移动平均(EMA)的优化器如Adam和AdamW时。这些优化器可能在处理超大规模数据集和复杂模型时无法有效捕捉梯度变化趋势,导致模型陷入局部优解。为解决这一问题,苹果和瑞士洛桑联邦理工学院的研究人员提出了AdEMAMix优化器,通过结合两种不同速率的EMA实现局部和全局优化。
AdEMAMix优化器的创新在于重新思考动量估计。传统Adam优化器中,动量通过单一EMA实现,这在处理历史梯度信息时存在局限性。AdEMAMix引入了两种EMA:快速变化的EMA对近期梯度变化反应灵敏,慢速变化的EMA对历史梯度给予更高权重,使优化器能在保持对近期变化敏感的同时有效利用长期积累的历史信息。
AdEMAMix还引入了一个参数调节慢速EMA在最终更新中的贡献,并通过精心设计的调度策略动态调整参数值。此外,AdEMAMix改进了传统的动量更新规则,通过结合两种EMA的更新向量调整模型参数,考虑了梯度的方向、大小和历史信息,使优化器能在复杂损失景观中更有效地寻找最优解。
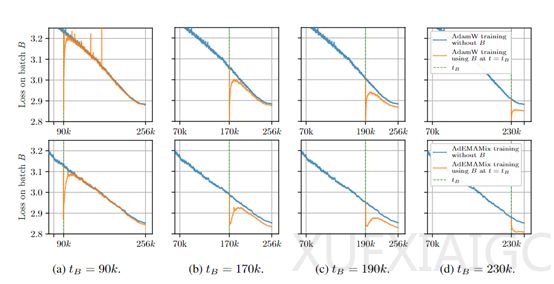
研究人员对Transformer、Mamba和VIT三种不同架构的大模型进行了综合测试,评估AdEMAMix优化器的性能。在Transformer模型测试中,AdEMAMix在不同规模的模型上均减少了训练时间和提高了性能。在Mamba模型测试中,AdEMAMix也取得了优异成绩,证明了该方法的可扩展性。在VIT模型测试中,AdEMAMix在不同参数规模的模型上均能较容易地找到优于传统优化器的参数设置,降低训练损失。这些测试结果表明,AdEMAMix优化器在不同类型的模型中均能提高训练效率和性能。
原文和模型
【原文链接】 阅读原文 [ 1078字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★☆☆☆☆


相关文章


