苹果也在蒸馏大模型,给出了蒸馏Scaling Laws
文章摘要
【关 键 词】 知识蒸馏、模型压缩、扩展定律、计算优化、性能预测
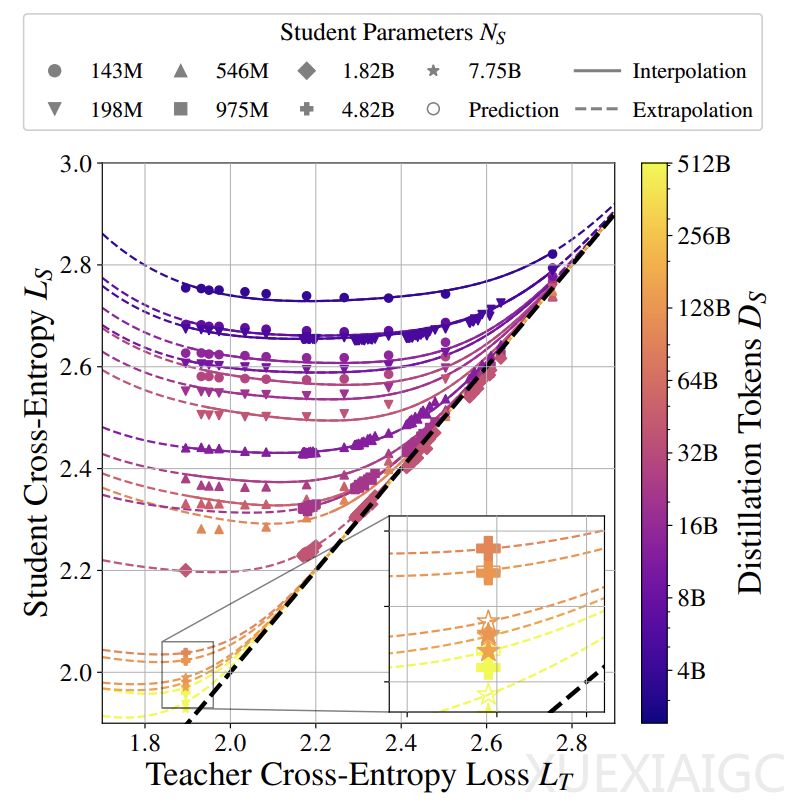
苹果研究人员提出的蒸馏扩展定律为量化评估知识蒸馏效果提供了理论框架。该定律通过计算预算在教师模型与学生模型之间的分配关系,能够预测不同配置下学生模型的交叉熵性能。研究发现,当教师模型的交叉熵损失L_T与学生模型的学习能力存在适当差距时,学生模型的表现可以超越教师模型,这种现象揭示了知识蒸馏中”弱到强泛化”的可能性。
实验验证了三个核心结论:首先,学生模型交叉熵可通过公式准确预测,其性能与教师模型参数N_T、训练数据量D_T呈强关联;其次,教师模型性能对学生模型的影响遵循幂律关系,这种关系会因两者能力差距发生形态转变;第三,能力差距的本质源于模型假设空间和优化能力的差异,而非单纯的规模差异。研究覆盖了1.43亿到126亿参数的模型规模,训练数据量最高达5120亿token,确保了结论的普适性。
在计算资源分配策略方面,研究提出了关键指导原则:当需要训练多个学生模型或已有现成教师模型时,蒸馏策略在计算效率上优于监督学习;但若需同时训练教师和学生模型,则监督学习更具优势。计算最优方案取决于学生模型规模与总计算预算的比值,存在明确的计算阈值决定策略选择。这种量化关系为实际应用提供了明确的决策依据。
实验设计采用多维度验证策略,包括固定模型规模的IsoFLOP配置、变化数据量的对比研究,以及不同师生模型组合的交叉验证。通过设置λ=1的纯蒸馏环境和τ=1的最优温度参数,研究排除了数据混合比例和温度调节的干扰,证实了教师模型质量对蒸馏效果的决定性作用。数据表明,当师生模型遵循Chinchilla最优配置时,学生模型在特定条件下可实现超越教师的表现。
该研究对产业实践具有显著指导价值:一方面为模型压缩提供了量化评估工具,另一方面揭示了知识传递的临界条件。当总计算预算低于特定阈值且教师模型可重复使用时,蒸馏策略能显著降低推理成本和总体计算开销。研究还指出,过度强大的教师模型可能因能力差距过大而降低知识传递效率,这为教师模型的选择提供了新的评估维度。这些发现为构建高效AI系统提供了理论支撑,特别是在平衡模型性能与计算成本的关键问题上给出了可操作的解决方案。
原文和模型
【原文链接】 阅读原文 [ 2555字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章




