文章摘要
【关 键 词】 AI通信、硅光子、CPO技术、光互连、数据中心
随着AI GPU集群对通信需求的不断增长,人们正转向使用光进行跨网络层通信。Nvidia宣布其下一代机架级AI平台将采用硅光子互连技术与共封装光学器件(CPO),并在今年的Hot Chips大会上发布了有关下一代Quantum – X和Spectrum – X光子互连解决方案的更多信息,计划于2026年上市。
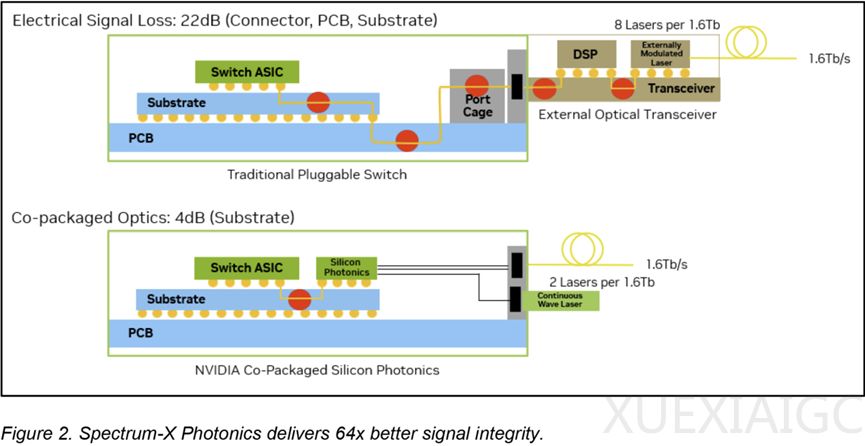
CPO的必要性:在大规模AI集群中,服务器与交换机距离延长,铜缆在高速下不适用,需光纤连接。可插拔光模块存在局限性,数据信号传输会产生严重电损耗,增加端口功耗与潜在故障点,随着AI部署规模扩大,损耗难以承受。而CPO将光转换引擎与交换机ASIC并排嵌入,避免了传统可插拔光模块的缺点,降低了电气损耗和每端口功耗,简化了光互连实施。Nvidia称采用CPO在效率、可靠性和可扩展性方面有显著提升,功率效率提高3.5倍,信号完整性提高64倍等。
以太网和InfiniBand的CPO平台:Nvidia将推出基于CPO的光互连平台,适用于以太网和InfiniBand技术。2026年初将推出Quantum – X InfiniBand交换机,每台提供115 Tb/s吞吐量,支持144个800 Gb/s端口,集成ASIC有网络内处理能力,支持第四代SHARP协议,采用液冷散热。2026年下半年通过Spectrum – X Photonics平台将CPO引入以太网,基于Spectrum – 6 ASIC的两款设备也采用液冷技术。基于CPO的交换机将为生成式AI应用提供支持,减少分立组件,提升集群在启动时间等方面的指标。Nvidia强调CPO是未来AI数据中心的结构性要求,也是超越竞争对手的关键优势。
未来发展:Nvidia的硅光子计划与台积电COUPE平台发展紧密契合。COUPE发展分三个阶段,第一代用于OSFP连接器的光学引擎,数据传输率达1.6 Tb/s,提升了带宽和能效;第二代集成到CoWoS封装,实现6.4 Tb/s的主板级光互连;第三代目标传输速率达12.8 Tb/s,集成到处理器封装,处于探索阶段,台积电还考虑进一步降低功耗和延迟。
原文和模型
【原文链接】 阅读原文 [ 1686字 | 7分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★☆☆


相关文章




