英伟达玩转剪枝、蒸馏:把Llama 3.1 8B参数减半,性能同尺寸更强
文章摘要
【关 键 词】 超大型模型、小型语言模型、知识蒸馏、模型剪枝、性能优化
Meta公司推出的Llama 3.1系列模型,包括一个405B的超大型模型和两个较小的模型,虽然性能卓越,但对计算资源的需求巨大。为解决这一问题,业界开始关注小型语言模型(SLM),它们在多种语言任务中表现出色且成本低廉。英伟达的研究显示,结合结构化权重剪枝和知识蒸馏技术,可以从较大的初始模型中逐步提炼出较小的语言模型。该研究得到了图灵奖得主、Meta首席AI科学家Yann LeCun的认可。
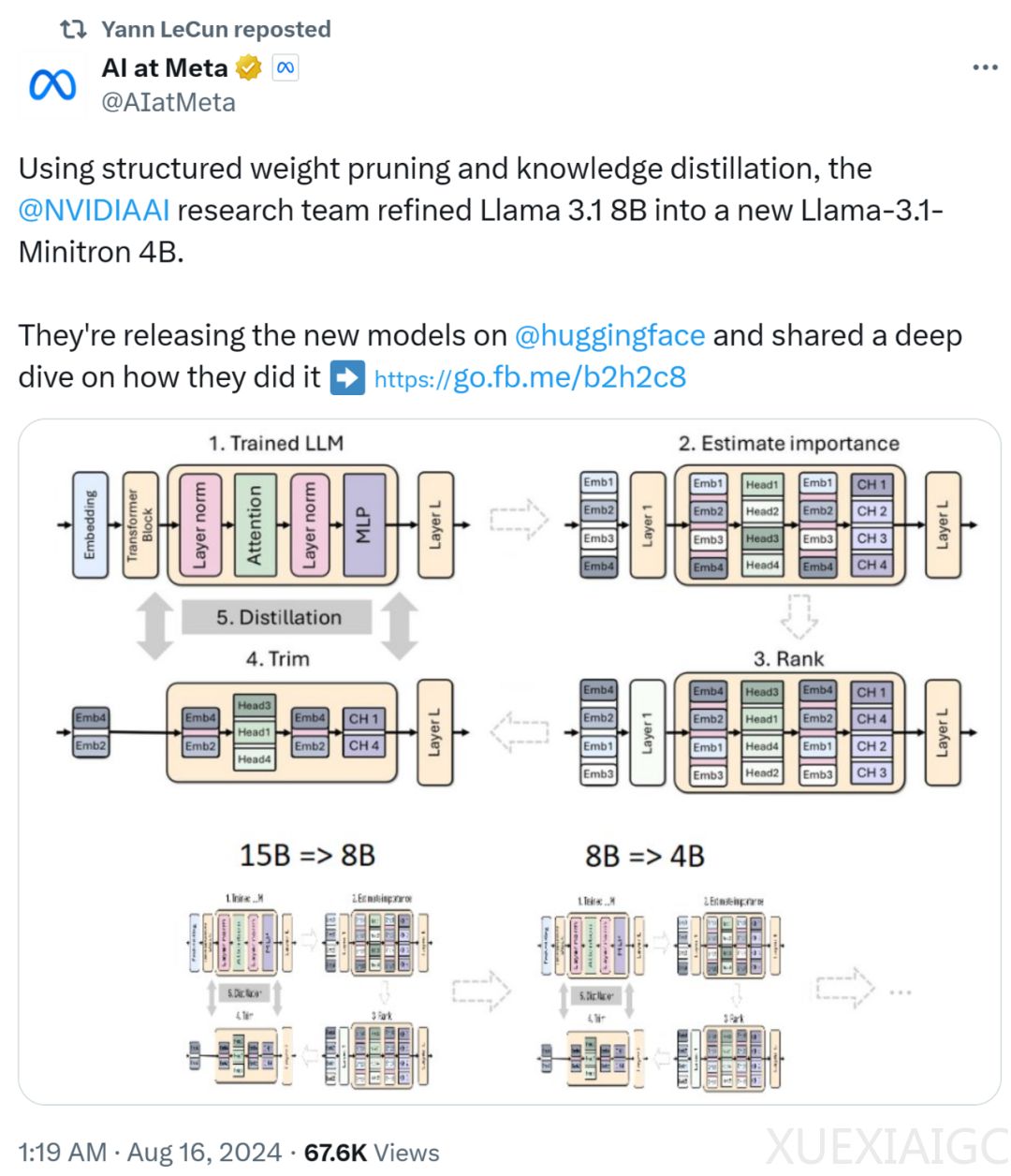
英伟达的研究团队通过剪枝和蒸馏过程,将Llama 3.1 8B模型提炼为Llama-3.1-Minitron 4B模型,并已开源。Llama-3.1-Minitron 4B在性能上超越了其他类似大小的先进开源模型。剪枝通过删除模型中的层或神经元等组成部分,使模型更小更精简,而模型蒸馏则是将大型模型的知识迁移到更小的学生模型中,以创建一个既高效又保留大部分预测能力的模型。
在剪枝过程中,英伟达采用了基于激活的纯重要性评估策略,通过前向传播计算各组成部分的重要性,这种方法简单且具有成本效益。英伟达还发现,使用单次重要性估计已足够,无需迭代估计。在蒸馏过程中,学生模型通过最小化嵌入输出损失、logit损失和Transformer编码器特定损失的组合来学习。
英伟达总结了剪枝和知识蒸馏的最佳实践,包括调整大小、剪枝和重新训练的策略。在调整大小时,应首先训练最大的模型,然后通过迭代剪枝和蒸馏获得较小的模型。剪枝时,宽度剪枝比深度剪枝更有效,且单样本重要性估计已足够。重新训练时,应使用蒸馏损失而非常规训练。
Llama-3.1-Minitron 4B模型是英伟达将最佳实践应用于Llama 3.1 8B模型的成果。在教师微调阶段,英伟达对8B模型进行了数据集偏差校正。在Depth-only剪枝中,英伟达评估了各层的重要性,并剪枝了16层。Width-only剪枝则针对嵌入和MLP中间维进行了压缩。准确率基准测试显示,Llama-3.1-Minitron 4B在多个领域的基准测试中表现优于其他类似大小的模型。
性能基准测试中,英伟达使用NVIDIA TensorRT-LLM优化了Llama 3.1 8B和Llama-3.1-Minitron 4B模型。结果显示,Llama-3.1-Minitron 4B模型在不同用例下的吞吐量显著高于Llama 3.1 8B模型。此外,Llama-3.1-Minitron 4B模型在指令遵循、角色扮演、RAG和函数调用功能上的表现也优于其他基线SLM。
总之,剪枝和经典知识蒸馏是一种经济高效的方法,可以逐步获得更小尺寸的LLM,并在所有领域实现更高的准确性。Llama-3.1-Minitron 4B模型的成功展示了这一方法的有效性,并为未来LLM的优化提供了新的方向。
原文和模型
【原文链接】 阅读原文 [ 2639字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


