作者信息
【原文作者】 AIGC开放社区
【作者简介】 专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
【微 信 号】 AIGCOPEN
文章摘要
【关 键 词】 ConsiStory模型、文生图、主体驱动自注意力、特征注入、锚图像
摘要总结:
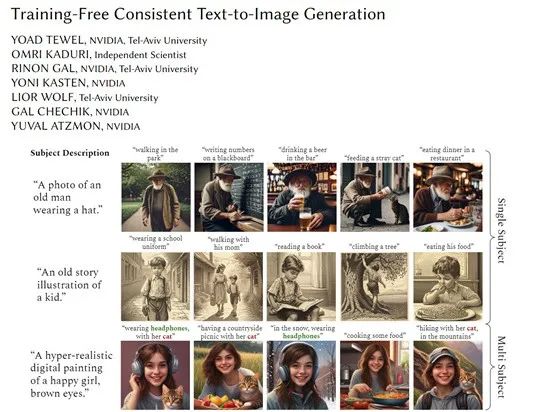
本文介绍了由英伟达和特拉维夫大学研究人员开发的ConsiStory模型,这是一个免训练一致性连贯文生图模型,旨在解决当前文生图模型在生成连贯图像方面的不足。ConsiStory模型的核心优势在于能够在不进行额外训练或调优的情况下,实现图像中主体的一致性。这一模型即将开源,论文地址为https://arxiv.org/abs/2402.03286。
目前,大多数文生图模型采用随机采样模式,导致生成的图像效果每次不同,难以实现连贯的图像生成。尽管DALL·E 3和Midjourney能够实现连贯的图像生成控制,但它们都是闭源产品。ConsiStory模型通过共享和调整模型内部表示,解决了这一问题。
ConsiStory模型的主要创新点包括:
1. 主体驱动自注意力(SDSA):这是ConsiStory的核心模块,通过扩大扩散模型中的自注意力层,允许一个图像中的提示词关注批次中其他图像的主体区域输出结果,实现主体视觉特征的共享和对齐。
2. 特征注入:基于扩散特征空间建立的密集对应图,用于在图像之间共享自注意力输出特征,确保主体相关的纹理、颜色等细节特征在整个批次中保持一致。
3. 锚图像和可重用主体:锚图像提供主题信息参考,引导图像生成过程,确保主题一致性。可重用主体则通过共享预训练模型的内部激活实现主题一致性,无需对外部图像进行对齐。
ConsiStory模型的这些特点使其成为一种插件,可以轻松集成到其他扩散模型中,提升文生图的一致性和连贯性。此外,ConsiStory实现了零训练成本,避免了传统方法中针对每个主题进行训练的难题。本文内容来源于ConsiStory论文,如有侵权请联系删除。
原文信息
【原文链接】 阅读原文
【原文字数】 1200
【阅读时长】 4分钟

相关文章





