作者信息
【原文作者】 努力犯错玩AI
【作者简介】 为AI开发者打造HuggingFace国内镜像站,提供最新流行开源模型资讯并免费加速下载。更多内容请访问https://aifasthub.com
【微 信 号】 gh_7709874d3358
文章摘要
【关 键 词】 大模型微调、Block Expansion、LLaMA Pro、知识遗忘、多任务处理
感谢总结,以下是对文章中重要词语和语句的标记:
1. 引言:大模型微调中的挑战
– 大型语言模型(LLM)的微调在提升模型性能上起着关键作用,但面临知识遗忘的挑战。
– 香港大学的研究团队联合腾讯ARC实验室提出了一种新的微调方法——Block Expansion,并开发了新型模型LLaMA Pro。
2. 微调传统方法的局限性
– 传统的大模型微调方法存在知识遗忘问题,限制了在多任务和持续学习场景下的应用。
3. Block Expansion:一种创新的解决方案
– Block Expansion方法的核心思想是在保持预训练模型参数不变的基础上,增加新的模块来适应新的训练任务。
4. LLaMA Pro模型的构建与特性
– LLaMA Pro模型在LLaMA2-7B模型的基础上增加了8个新模块,使参数量达到83亿,在多个任务上表现出色。
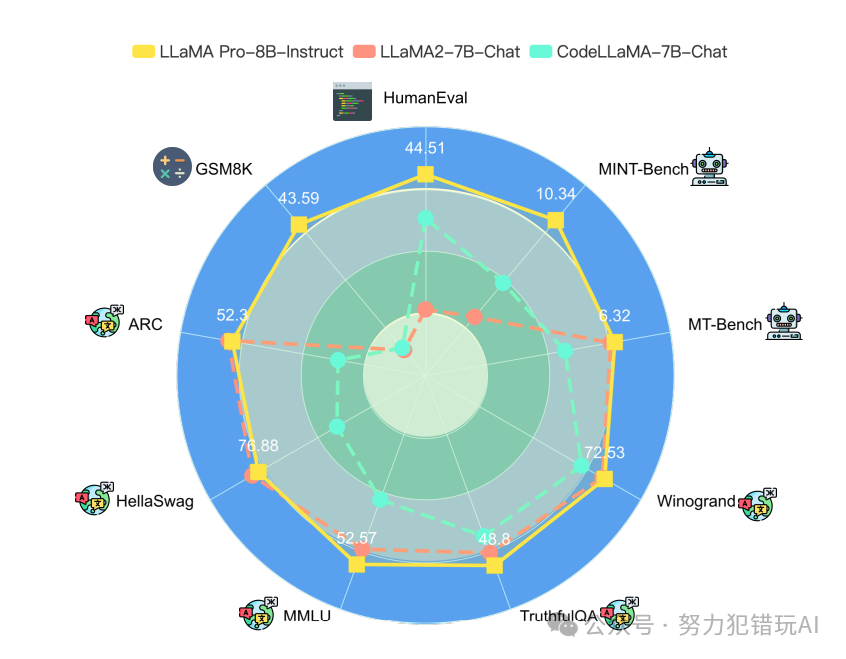
5. LLaMA Pro的实验评测与结果分析
– LLaMA Pro在不同数据集上取得显著进步,尤其在代码和数学推理方面表现突出。
6. 与传统微调方法的对比
– Block Expansion方法与传统的有监督微调方法进行对比,结果显示LLaMA Pro在持续学习和多任务处理能力上优于传统方法。
7. 结论与展望
– Block Expansion方法有效缓解了大模型微调中的知识遗忘问题,LLaMA Pro模型在特定领域任务上表现显著,可能成为替代传统微调方法的新选择。
原文信息
【原文链接】 阅读原文
【原文字数】 1233
【阅读时长】 5分钟

相关文章





