文章摘要
【关 键 词】 腾讯音乐、开源项目、虚拟人类、动作生成、音频驱动
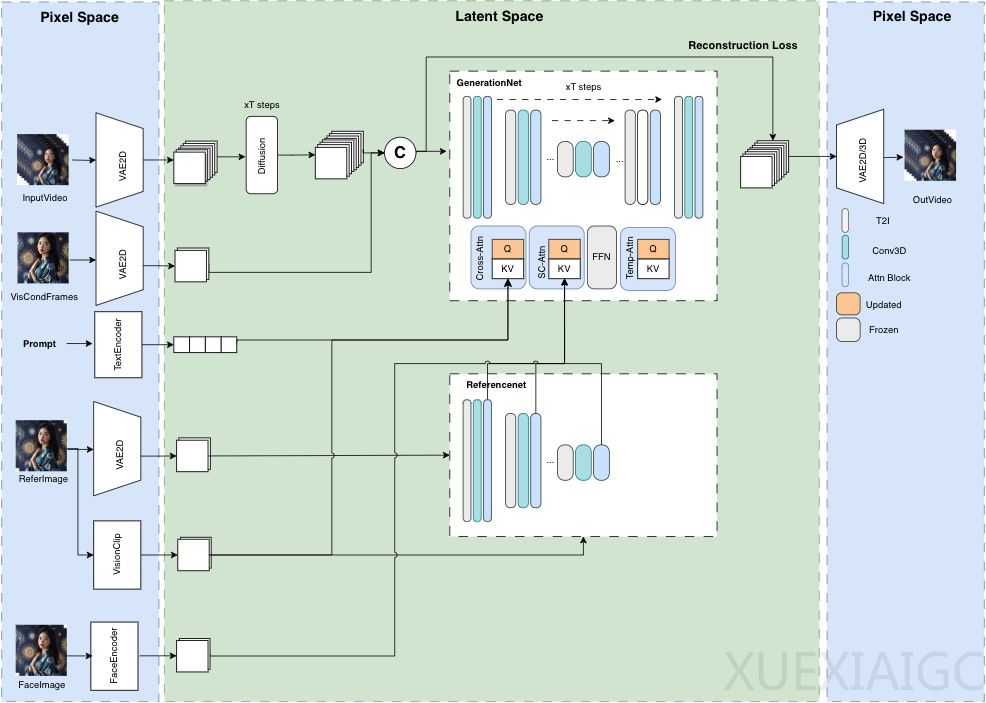
腾讯音乐娱乐的Lyra Lab团队开发了一个名为Muse的开源系列项目,致力于虚拟人类的生成。其中的最后一个模块MusePose,已于5月27日正式发布,标志着Muse系列数字人开源框架的完整构建。MusePose是一个姿态驱动的图像到视频生成框架,专注于虚拟人类的舞蹈视频生成,能够根据给定的姿态序列生成参考图像中人物的动画。
在MusePose之前,腾讯已发布了MuseV和MuseTalk两个项目。MuseV是一个基于扩散的虚拟人视频生成框架,可以基于文本描述或静态图像生成视频。而MuseTalk是一个实时高质量音频驱动的口型同步模型,能够在潜在空间中对面部区域进行修改,匹配输入的音频,并实现每秒30帧以上的实时处理速度。MuseV和MuseTalk的协同工作可以实现虚拟人类的全身运动和互动能力。
MusePose与MuseV的区别在于,MuseV的视频动作随机性较大,而MusePose是按照给定的动作生成,动作固定。MusePose需要更高的显存(12G以上),生成的视频在清晰度和稳定性上可能略逊于MuseV。关键的技术之一是姿态对齐算法,它能确保生成的视频中的人物动作与输入的姿态序列一致。
此外,社区已经开发了对应的ComfyUI插件来支持MusePose的工作流。MusePose、MuseV和MuseTalk共同构建了Muse生态,旨在提供一个完整的虚拟人类生成解决方案,从动态捕捉到视觉内容的生成,再到声音与形象的融合。
最后,腾讯在发布Muse系列项目的同时,也对阿里的Animate Anyone开源项目表示了感谢,似乎表明两者之间有所启发和借鉴。
原文和模型
【原文链接】 阅读原文 [ 3390字 | 14分钟 ]
【原文作者】 硅星人Pro
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章



