腾讯混元、英伟达都发混合架构模型,Mamba-Transformer要崛起吗?
文章摘要
【关 键 词】 Transformer、Mamba、混合架构、推理模型、深度学习
近年来,Transformer架构在自然语言处理领域取得了显著成就,但其计算复杂度和内存占用问题逐渐成为瓶颈。与此同时,Mamba作为一种新兴的状态空间模型(SSM),凭借其高效处理长序列数据的能力,成为Transformer的有力竞争者。然而,这两种架构并非完全对立,而是逐渐走向融合,形成了Mamba-Transformer混合架构。这一架构在降低计算复杂度和内存占用的同时,显著提升了模型的推理速度和效率。
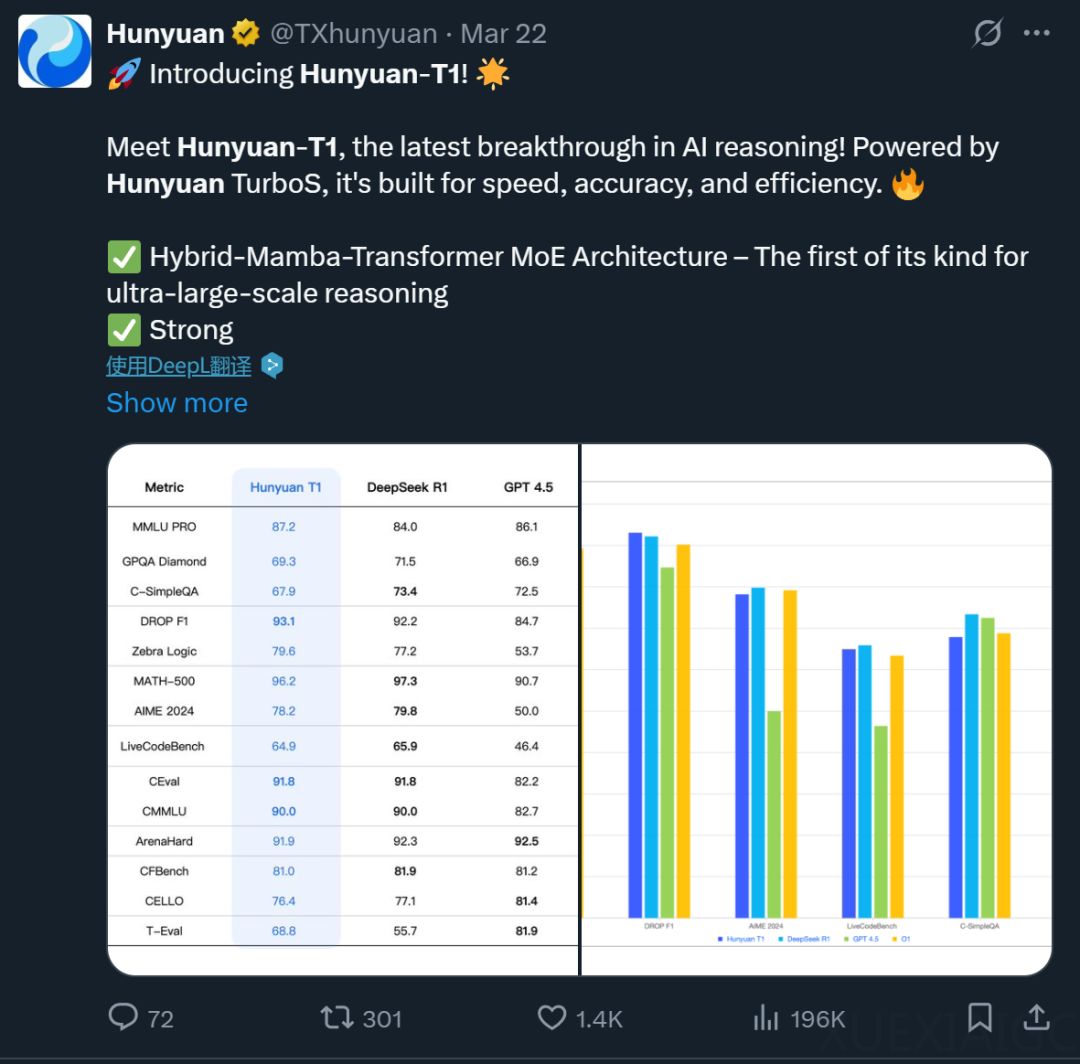
腾讯推出的自研深度思考模型“混元 T1”正式版,正是基于Hybrid-Mamba-Transformer融合架构。该模型在超长文本处理、数学推理、逻辑推理等领域表现出色,首字秒出,吐字速度最快可达80 token/s。混元 T1通过降低KV-Cache的内存占用,显著减少了训练和推理成本,成为工业界首次将混合Mamba架构无损应用于超大型推理模型的典型案例。在多项基准测试中,混元 T1的成绩均达到业界领先水平,尤其是在MMLU-PRO数据集上取得了87.2分的高分。
英伟达也推出了采用Mamba-Transformer混合架构的模型家族Nemotron-H,其推理速度是同体量竞品模型的三倍。Nemotron-H系列模型在保证准确度的同时,大幅提升了计算效率,尤其是在长上下文推理任务中表现出色。例如,Nemotron-H-47B-Base模型可以在单台商品级NVIDIA RTX 5090 GPU上支持100万token长度的推理任务。此外,英伟达还公布了Nemotron-H-56B-Base的训练细节,该模型使用了6144台H100 GPU和20万亿token进行训练,展示了FP8预训练的大规模应用。
Mamba-Transformer混合架构的成功,不仅体现在推理速度和效率的提升上,还在于其能够有效解决长序列处理中的上下文丢失和长距离信息依赖问题。Mamba通过选择机制和硬件感知型算法,能够在滤除不相关信息的同时保留必要数据,并通过扫描而非卷积的方式大幅提升计算速度。这种架构的线性可扩展性使其在处理长序列数据时具有显著优势,尤其是在视频理解和多模态任务中。
英伟达的STORM模型进一步展示了Mamba在视频处理中的应用潜力。STORM是一种基于视频的多模态大型语言模型,通过引入时间编码器,将视觉和语言表征整合在一起。Mamba状态空间模型作为时间层的核心,能够高效处理长视频,并增强对时间上下文的泛化能力。实验表明,STORM在长上下文视频理解任务中表现出色,同时保持了较高的训练效率。
总体而言,Mamba-Transformer混合架构的出现,标志着AI大模型在计算效率和推理速度上的重大突破。腾讯和英伟达等科技巨头对这一架构的高度关注和投入,预示着其在未来AI应用中的广阔前景。随着技术的不断演进,Mamba-Transformer混合架构有望在更多领域实现突破,推动AI技术的普及和应用。
原文和模型
【原文链接】 阅读原文 [ 4056字 | 17分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章




