美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源
文章摘要
【关 键 词】 AI模型、开源资源、去中心化、大规模训练、全球合作
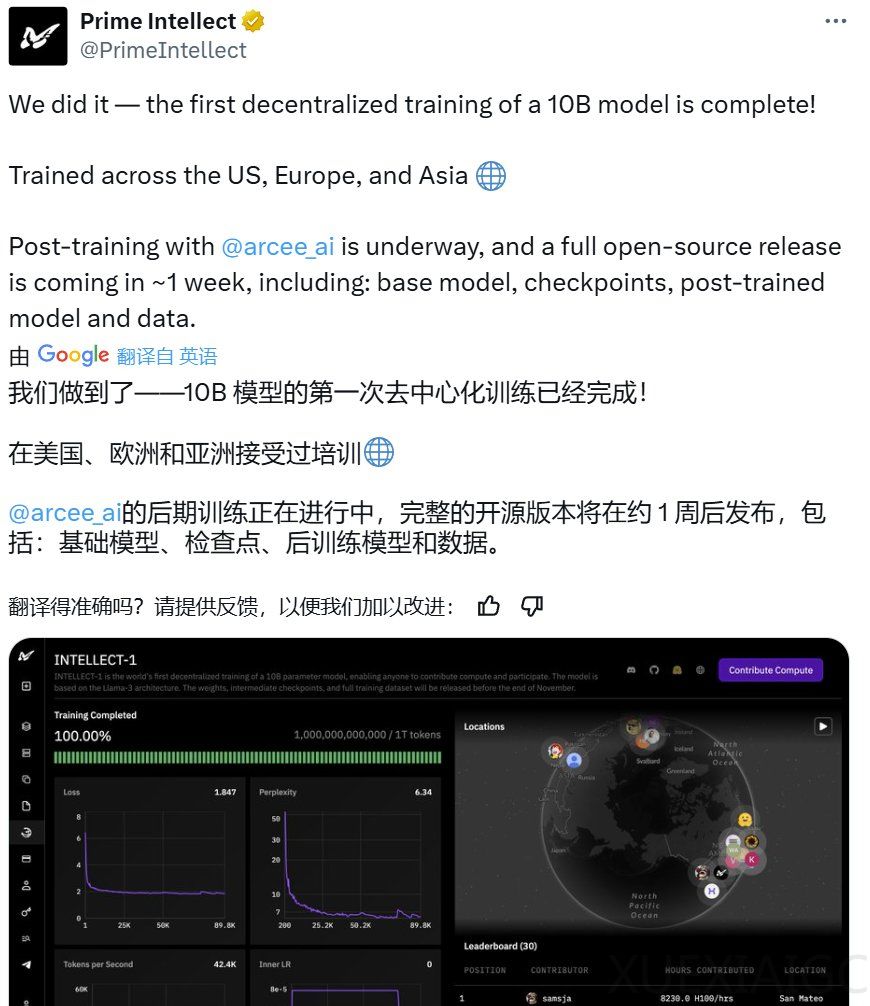
Prime Intellect在11月22日宣布完成了一个10B参数规模的模型INTELLECT-1的训练,并通过去中心化的方式开源了所有相关资源,包括基础模型、检查点、后训练模型、数据、PRIME训练框架和技术报告。这一成就标志着大规模模型训练不再仅限于大型公司,社区驱动的去中心化方式同样可行。INTELLECT-1在规模上实现了10倍的提升,AI社区对此反应积极,尽管存在一些质疑。
INTELLECT-1基于Llama-3架构,包含42层,隐藏维度为4,096,32个注意力头,序列长度为8,192,词表大小为128,256。模型在1万亿token的数据集上训练,数据集包括FineWeb-Edu、Stack v2、FineWeb、DCLM-baseline和OpenWebMath。训练持续了42天,采用了WSD动态调整学习速度、精细调教的学习参数、特殊的损失函数、Nesterov动量优化算法等技术,支持训练机器的灵活接入和退出。
Prime Intellect的去中心化训练涉及3个大洲的5个国家,运行了112台H100 GPU,实现了83%的总体计算利用率。训练框架Prime基于OpenDiLoCo,支持容错训练、计算资源的动态开启/关闭,并优化全球分布式GPU网络中的通信和路由。Prime框架的关键特性包括ElasticDeviceMesh、异步分布式检查点、实时检查点恢复、自定义Int8 All-Reduce内核等。
后训练阶段,Prime Intellect与Arcee AI合作,通过SFT、DPO和使用MergeKit整合训练成果来提升INTELLECT-1的能力。Prime Intellect的长期目标是实现开源AGI,并计划通过扩大全球计算网络、激励社区参与和优化PRIME架构来支持更大的模型。团队邀请全球AI社区加入,共同构建一个更开放、更具协作性的AI发展未来。
原文和模型
【原文链接】 阅读原文 [ 2113字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




