给视频模型安上快慢两只眼睛,苹果免训练新方法秒了一切SOTA
文章摘要
【关 键 词】 AI视频生成、SF-LLaVA模型、双流网络、视频问答、时间理解
Sora的发布标志着AI视频生成领域的新发展,近期涌现的AI视频生成模型在质量上取得了显著进步,与以往容易被识别的AI生成视频相比,新一代模型展现出更高的真实度。然而,这些高质量的视频生成模型背后依赖于庞大且精细标注的视频数据集,这不仅成本高昂,而且现有模型存在处理视频输入帧数有限和缺少时间建模设计的问题。
为解决这些问题,苹果研究人员提出了一种名为SlowFast-LLaVA(SF-LLaVA)的新型视频生成模型。该模型基于字节团队开发的LLaVA-NeXT架构,无需额外微调即可直接使用。SF-LLaVA采用了双流网络的设计思想,通过慢速和快速两种观察速度来同时理解视频中的细节和运动。
具体来说,SF-LLaVA的慢速路径以较低帧率提取特征,尽可能保留空间细节;而快速路径则以较高帧率运行,通过较大的空间池化步长降低分辨率,以模拟更大的时间上下文,更专注于动作连贯性的理解。这种设计使得SF-LLaVA能够同时捕捉视频中的详细空间语义和长时间上下文信息。
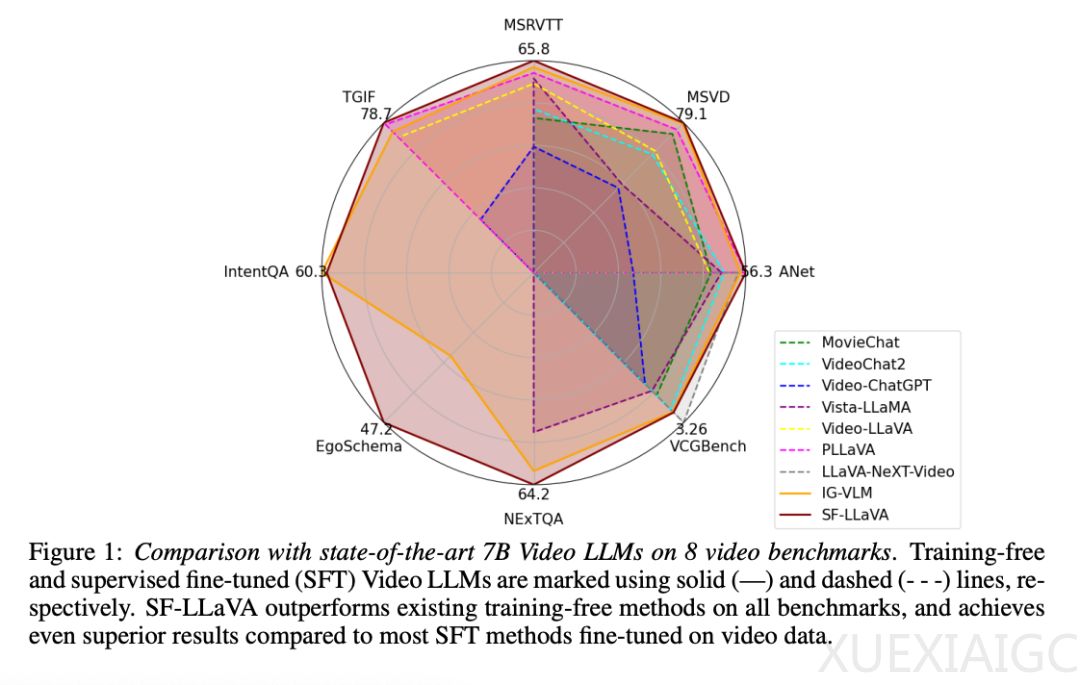
实验结果表明,SF-LLaVA在多个视频问答任务的基准测试中均显著优于现有的免训练方法。即使与经过精心微调的模型相比,SF-LLaVA也能达到相同甚至更好的性能。在模型架构上,SF-LLaVA遵循标准的免训练视频LLM流程,输入视频和问题,输出答案。通过慢速和快速路径的处理,SF-LLaVA能够有效地结合空间和时间特征,生成高质量的视频表示。
在开放式视频问答任务中,SF-LLaVA在MSRVTT-QA、TGIF-QA和ActivityNet-QA等基准测试中均优于现有的免训练方法。在多项选择视频问答任务中,SF-LLaVA在EgoSchema等数据集上的表现也优于其他免训练方法。此外,在文本生成视频任务中,SF-LLaVA同样展现出优势,尤其是在时间理解方面的表现。
总的来说,SF-LLaVA作为一种新型的视频生成模型,通过创新的SlowFast输入机制,有效地解决了现有模型在处理视频输入帧数和时间建模方面的局限性。实验结果证明了SF-LLaVA在多个视频任务中的优越性能,为AI视频生成领域的发展提供了新的思路和方法。更多关于SF-LLaVA的细节和实验结果,可以参考原论文。
原文和模型
【原文链接】 阅读原文 [ 1642字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章




