终于有人调查了小模型过拟合:三分之二都有数据污染,微软Phi-3、Mixtral 8x22B被点名
文章摘要
【关 键 词】 机器学习、模型评估、数据污染、过拟合、基准测试
背景介绍:
– 大型语言模型的推理能力提升是当前研究的重要方向。
问题提出:
– 许多研究使用GSM8k、MATH等测试集作为基准,但这些测试集可能受到训练数据集的污染,导致模型推理能力被错误评估。
研究方法和发现:
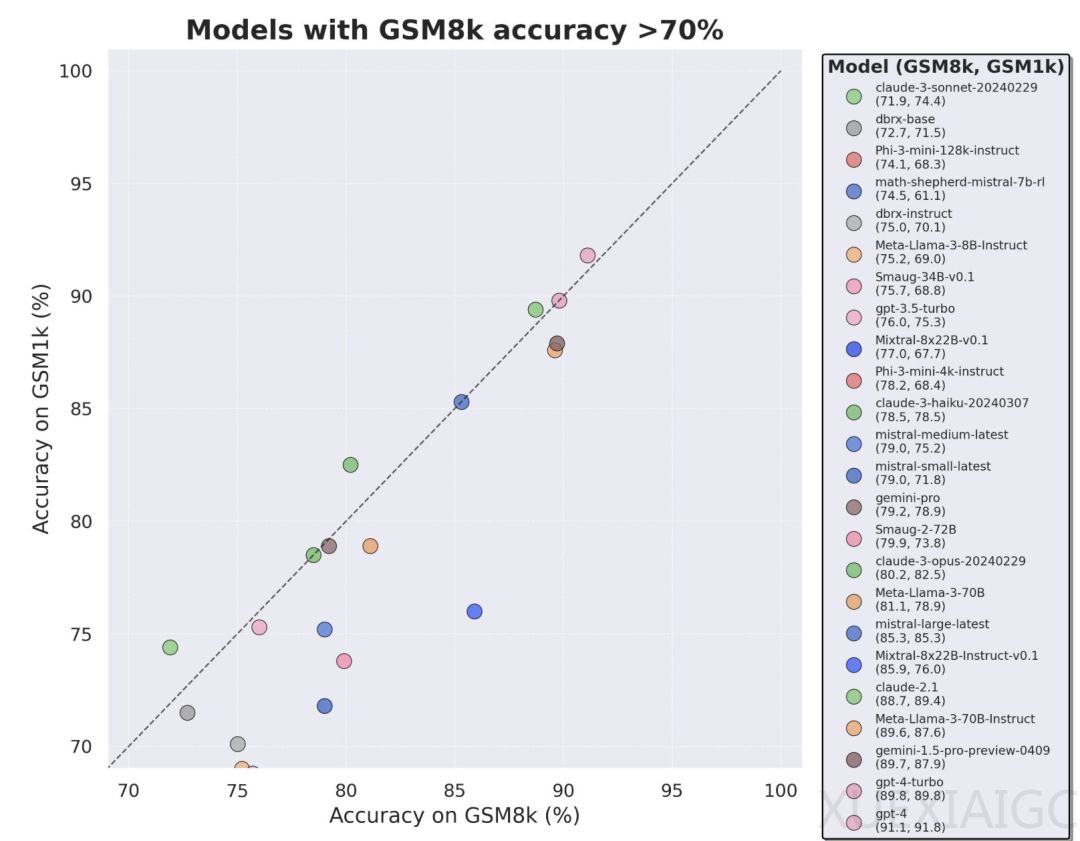
– 研究者发现许多模型受到基准数据的污染,尤其是Mistral和Phi模型系列显示出过拟合的一致证据。
– 在GSM1k上的测试结果显示,表现最差的模型性能比GSM8k低13%。
评估结果分析:
– 模型在GSM8k上的表现与在GSM1k上的表现差距存在正相关关系,表明过拟合的主要原因是模型部分背出了GSM8k中的样本。
GSM1k数据集:
– GSM1k包含1250道小学数学题,由人工注释者根据GSM8k样本问题提出难度相似的新问题构建。
评估方法和模型选择:
– 研究者使用EleutherAI的LM Evaluation Harness进行评估,所有模型在温度为0时进行评估以保证可重复性。
结论:
– 一些模型系列,如Phi和Mistral,显示出系统性过拟合。
– 其他模型,尤其是前沿模型,没有表现出过拟合的迹象。
– 过拟合的模型仍然具有推理能力,能够解决新问题。
未来展望:
– Scale AI承诺在满足一定条件后发布GSM1k数据集,并计划定期评估所有主要的开源和闭源LLM。
原文和模型
【原文链接】 阅读原文 [ 3836字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

