秒杀同行!Kimi开源全新音频基础模型,横扫十多项基准测试,总体性能第一
文章摘要
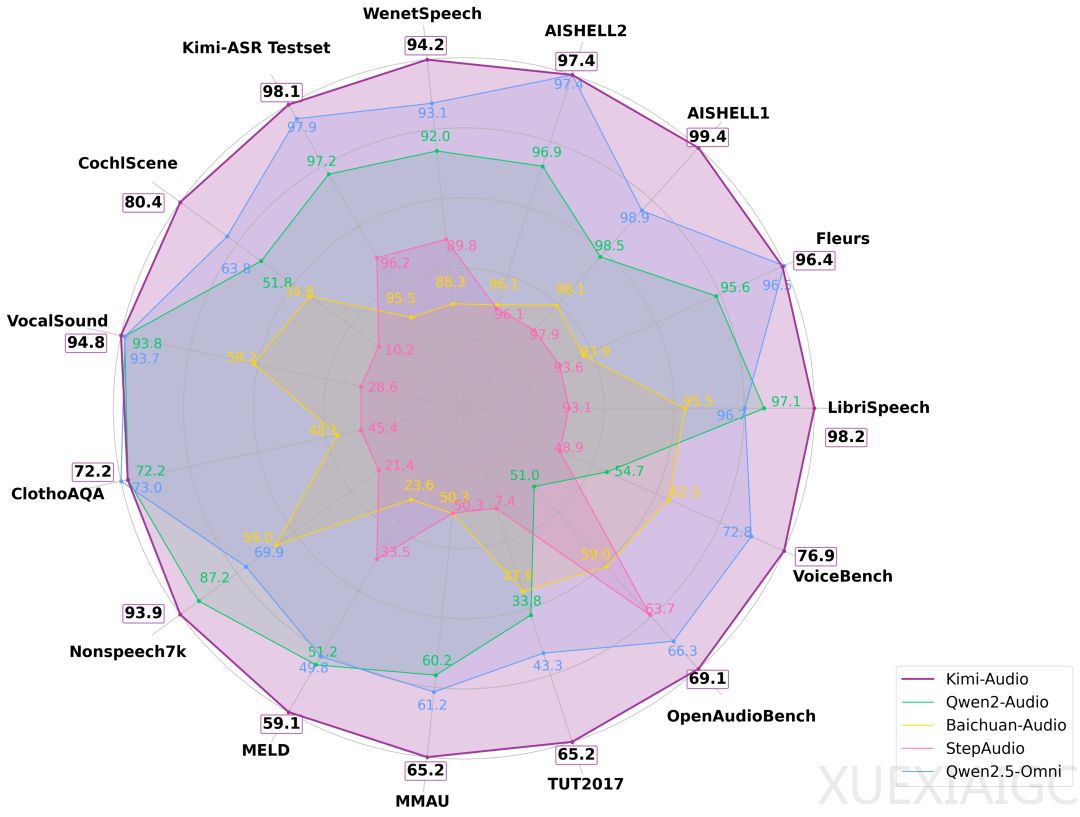
Kimi-Audio 是一个全新的通用音频基础模型,支持语音识别、音频理解、音频转文本、语音对话等多种任务,在多个音频基准测试中实现了最先进的性能。结果显示,Kimi-Audio 总体性能排名第一,几乎没有明显短板。例如,在 LibriSpeech ASR 测试上,Kimi-Audio 的词错误率(WER)仅为 1.28%,显著优于其他模型。在 VocalSound 测试上,Kimi-Audio 达到了 94.85% 的准确率,接近满分。此外,在 MMAU 任务中,Kimi-Audio 摘得两项最高分,并在 VoiceBench 评测中,在所有子任务中得分最高,包括一项满分。
Kimi-Audio 的架构设计包括三个核心组件:音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)和音频去分词器(Audio Detokenizer)。这种集成式架构使 Kimi-Audio 能够在单一模型框架下,流畅地处理多种音频语言任务。音频分词器负责将输入音频转化为离散语义 token,并提取连续的声学向量,以增强感知能力。音频大模型基于共享 Transformer 层,能够处理多模态输入,并在后期分支为专门用于文本和音频生成的两个并行输出头。音频去分词器使用流匹配方法,将音频大模型预测出的离散语义 token 转化为连贯的音频波形,生成高质量、具有表现力的语音。
在数据建构和训练方法方面,Kimi-Audio 在预训练阶段使用了约 1300 万小时覆盖多语言、音乐、环境声等多种场景的音频数据,并搭建了一条自动处理“流水线”生成高质量长音频-文本对。预训练后,模型进行了监督微调(SFT),数据涵盖音频理解、语音对话和音频转文本聊天三大类任务,进一步提升了指令跟随和音频生成能力。在训练方法上,研发人员以预训练语言模型为初始化,设计了三个类别的预训练任务:仅文本和仅音频预训练、音频到文本的映射、音频文本交错训练。在监督微调阶段,他们设计了一套训练配方,以提升训练效率与任务泛化能力。
评估结果显示,Kimi-Audio 在自动语音识别(ASR)、音频理解、音频转文本聊天和语音对话等任务中表现出色。在 LibriSpeech 基准测试中,Kimi-Audio 在 test-clean 上达到了 1.28 的错误率,在 test-other 上达到了 2.42,显著超越了其他模型。在音频理解任务中,Kimi-Audio 在 MMAU 基准测试中展现出卓越的理解能力,并在 MELD 语音情感理解任务上超越了其他模型。在音频到文本聊天任务中,Kimi-Audio 在 OpenAudioBench 和 VoiceBench 基准测试中实现了最先进的性能。在语音对话任务中,Kimi-Audio 在情感控制、同理心和速度控制方面均取得了最高分,整体平均得分高达 3.90,超过了其他对比模型。
目前,Kimi-Audio 的模型代码、模型检查点以及评估工具包已经在 Github 上开源,为研究人员和开发者提供了便捷的使用和评估工具。Kimi-Audio 的成功不仅展示了其在音频处理领域的强大能力,也为未来的音频模型研究提供了新的方向。
原文和模型
【原文链接】 阅读原文 [ 2420字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



