作者信息
【原文作者】 Hugging Face
【作者简介】 The AI community building the future.
【微 信 号】 Hugging-Face
文章摘要
【关 键 词】 推理速度、注意力模块、Colossal-AI、SwiftInfer、大模型
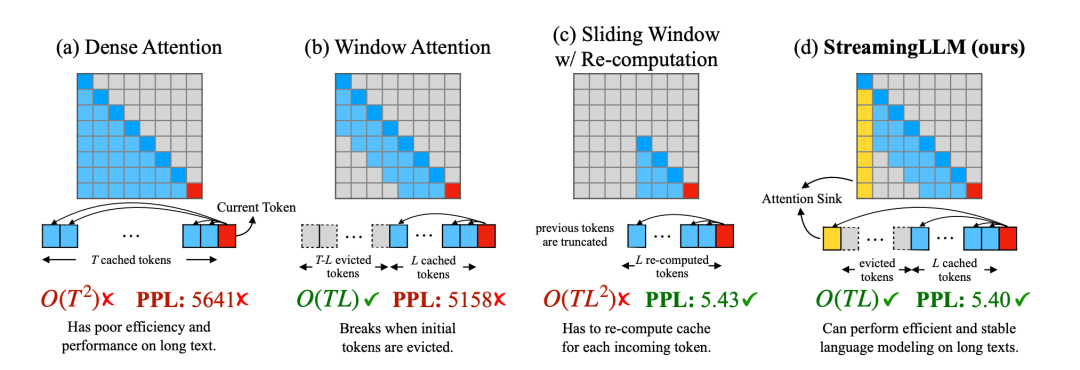
第一段:介绍了麻省理工Guangxuan Xiao等人推出的StreamingLLM,能够在多轮对话中实现400万个token的流式输入,并提升了推理速度22.2倍。
第二段:讲述了StreamingLLM的优势和挑战,以及其通过观察注意力模块中Softmax的输出,解决了注意力 sink 的现象,提高了生成效果。
第三段:介绍了Colossal-AI团队开源的SwiftInfer,基于TensorRT实现了StreamingLLM,进一步提升了大模型推理性能。
第四段:详细描述了SwiftInfer基于TensorRT-LLM重新实现了KV Cache机制以及带有位置偏移的注意力模块,提高了运行效率。
第五段:指出了SwiftInfer可以进一步提升推理性能,最多带来额外的46%的推理吞吐速度提升,为大模型多轮对话推理提供了低成本、低延迟、高吞吐的最佳实践。
第六段:介绍了Colossal-AI社区的动态,包括其在GitHub上的排名和开源的Colossal-LLaMA-2-13B模型。
第七段:讲述了MoE模型的优势以及Colossal-AI通过EZ-MoE等优化,可提升MoE模型训练效率9倍,并开源相关代码与模型。
原文信息
【原文链接】 阅读原文
【原文字数】 1518
【阅读时长】 6分钟
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



