真实联网搜索Agent,7B媲美满血R1,华为盘古DeepDiver给出开域信息获取新解法
文章摘要
【关 键 词】 大型语言模型、搜索引擎交互、强化学习、信息检索、知识密集型任务
华为诺亚方舟实验室提出的Pangu DeepDiver模型通过Search Intensity Scaling(SIS)技术,实现了大型语言模型(LLM)与搜索引擎的自主交互,显著提升了7B参数模型在开域信息获取任务中的表现。该模型在复杂知识密集型问题上展现出接近百倍参数规模模型DeepSeek-R1的能力,并优于同期其他研究。
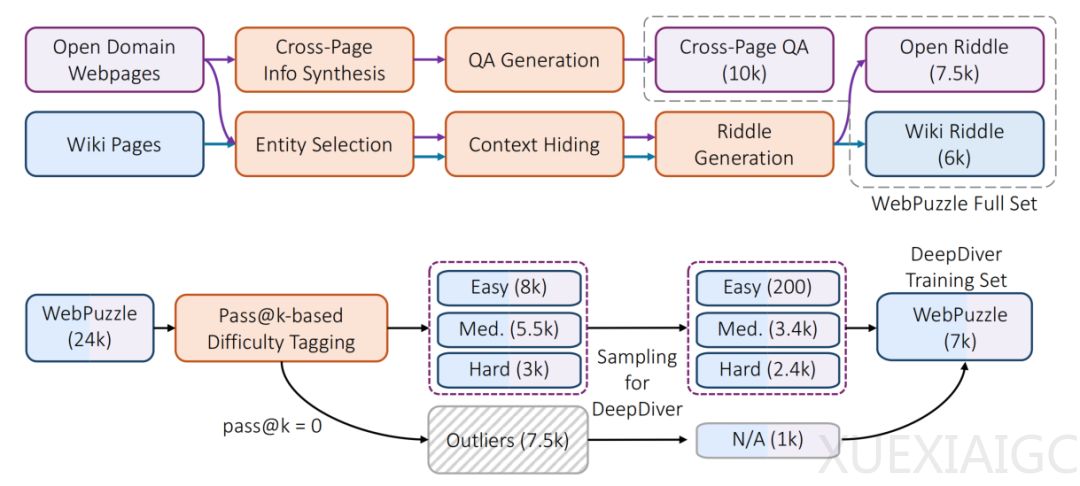
核心创新在于Agentic强化学习(RL)训练与真实互联网环境的结合。研究团队构建了高质量数据集WebPuzzle,包含24k训练样本和275条评测样本,涵盖跨页问答和模糊谜题。与基于Wikipedia的合成数据相比,真实互联网数据能更好地训练模型处理噪声、信息冲突及多轮验证等高阶能力。训练分为冷启动阶段(通过蒸馏教师模型学习基础能力)和RL阶段(通过GRPO算法自主探索),并设计了两阶段奖励机制:初期宽松奖励稳定训练,后期严格奖励突破性能瓶颈。
实验结果显示,DeepDiver在WebPuzzle上的准确率达38.1%,比蒸馏模型提升10个百分点。关键发现包括:1)SIS使模型能动态调整搜索轮次,问题难度越高,搜索强度越大;2)排除依赖内部知识的问题后,7B DeepDiver性能匹敌671B的DeepSeek-R1;3)模型在未训练的开放式长文生成任务(如ProxyQA)中表现优异,生成内容更全面。
与基于Wikipedia环境的同期工作对比,DeepDiver在英文任务中仍具优势,验证了SIS的泛化能力。行为分析表明,该模型在真实网络环境中表现出更复杂的检索策略,如多源验证和反思纠正。局限性包括WebPuzzle需持续更新以适应LLM知识扩展,以及开放式任务奖励设计的挑战。未来方向包括扩展工具生态(如浏览器引擎)、优化RL框架,并探究基座模型规模对SIS的影响。
DeepDiver为LLM在真实场景中的信息获取能力提供了新范式,证明小模型通过强化学习与动态搜索策略可媲美超大规模模型。其技术路径为Agentic RL在搜索增强生成(RAG)领域的应用提供了重要参考。
原文和模型
【原文链接】 阅读原文 [ 4098字 | 17分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章




