瑜伽球上遛「狗」!入选英伟达十大项目之一的Eureka有了新突破
文章摘要
【关 键 词】 DrEureka算法、机器人任务、模拟到现实、机器狗、四足机器人
这篇文章报道了一项由宾夕法尼亚大学、NVIDIA和得克萨斯大学奥斯汀分校的研究者联合进行的开源研究项目,该项目提出了一种名为DrEureka的新型算法。DrEureka利用大型语言模型(LLM)实现奖励设计和域随机化参数配置,以促进模拟到现实的迁移。这项研究展示了DrEureka算法在解决机器人任务,如四足机器人在瑜伽球上保持平衡和行走的能力,而无需手动设计迭代。
DrEureka基于Eureka算法,后者被评为2023年英伟达十大项目之一。Eureka算法因其简单性和表现力而被选中,但研究者对其进行了一些改进,以增强其在模拟到真实环境中的适用性。研究者指出,将模拟中学习到的策略迁移到现实世界是一种有前途的策略,但通常依赖于任务奖励函数和模拟物理参数的手动设计和调整,这使得过程缓慢且耗费人力。因此,他们研究了使用大型语言模型(LLM)来自动化和加速模拟到现实的设计。
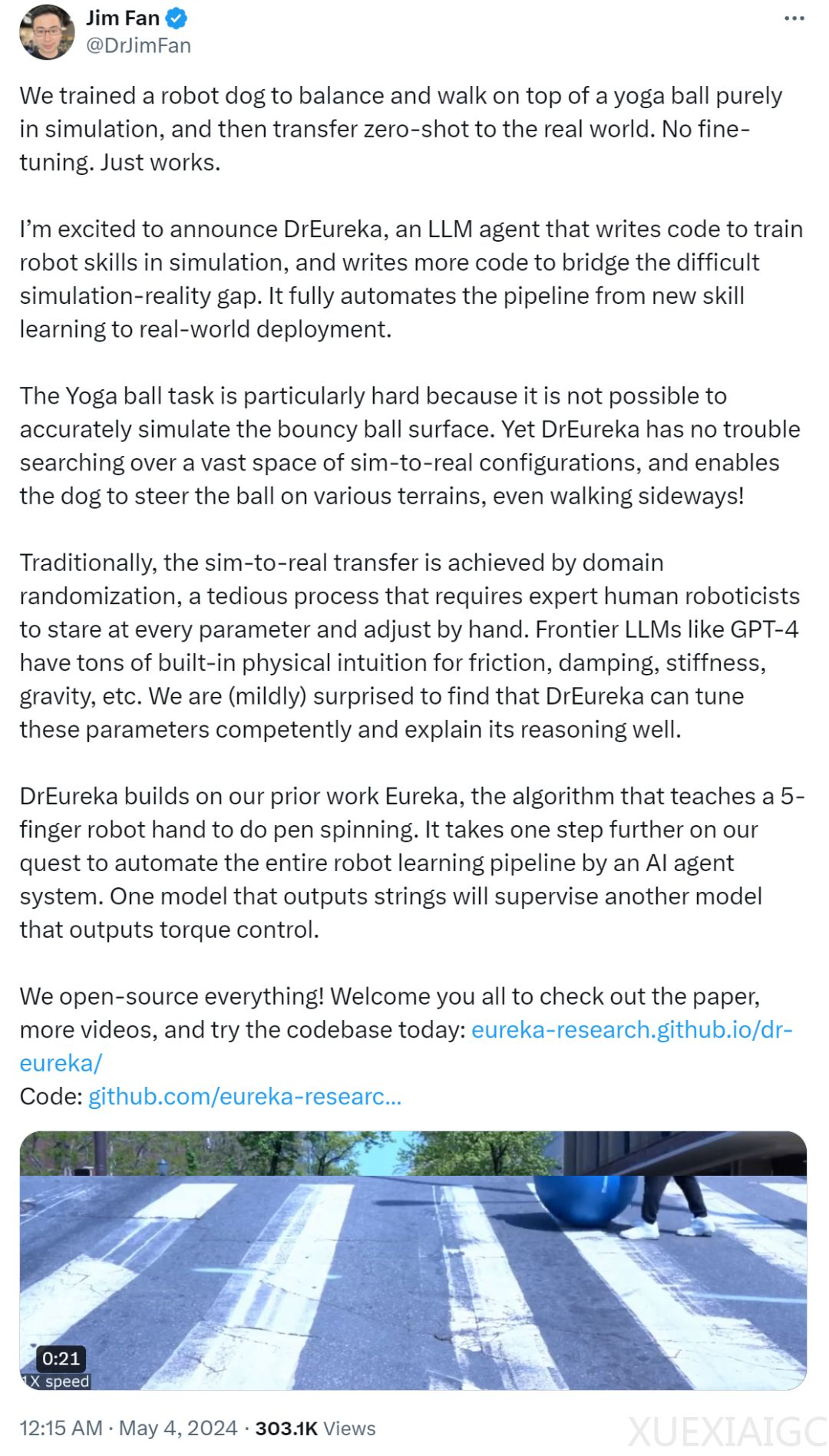
英伟达高级科学家Jim Fan参与了这项研究,他提到,他们训练了一只机器狗在瑜伽球上保持平衡并行走,这完全是在模拟中进行的,然后零样本迁移到现实世界,无需微调,直接运行。DrEureka可以轻松搜索大量模拟真实配置,并让机器狗能够在各种地形上操控球,甚至横着走。
DrEureka的流程包括接受任务和安全指令以及环境源代码,运行Eureka以生成正则化的奖励函数和策略,然后在不同的模拟条件下测试该策略以构建奖励感知物理先验,并将其提供给LLM以生成一组域随机化(DR)参数。最后,使用合成的奖励和DR参数训练策略以进行实际部署。
此外,研究者还引入了一种名为奖励感知物理先验(RAPP)的机制,以限制LLM的基本范围,并通过LLM在RAPP范围的限制内生成域随机化配置。
实验使用了Unitree Go1,一个小型四足机器人,具有12个自由度。研究者在几个现实世界地形上系统地评估了DrEureka策略的性能,发现它们具有鲁棒性,并且优于使用人类设计的奖励和DR配置训练的策略。
这项研究的成果展示了利用LLM进行模拟到现实迁移的潜力,为机器人技能的大规模获取提供了一种新的方法。
原文和模型
【原文链接】 阅读原文 [ 1681字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章



