猛击OpenAI o1、DeepSeek-R1!刚刚,阿里Qwen3登顶全球开源模型王座,深夜爆火
文章摘要
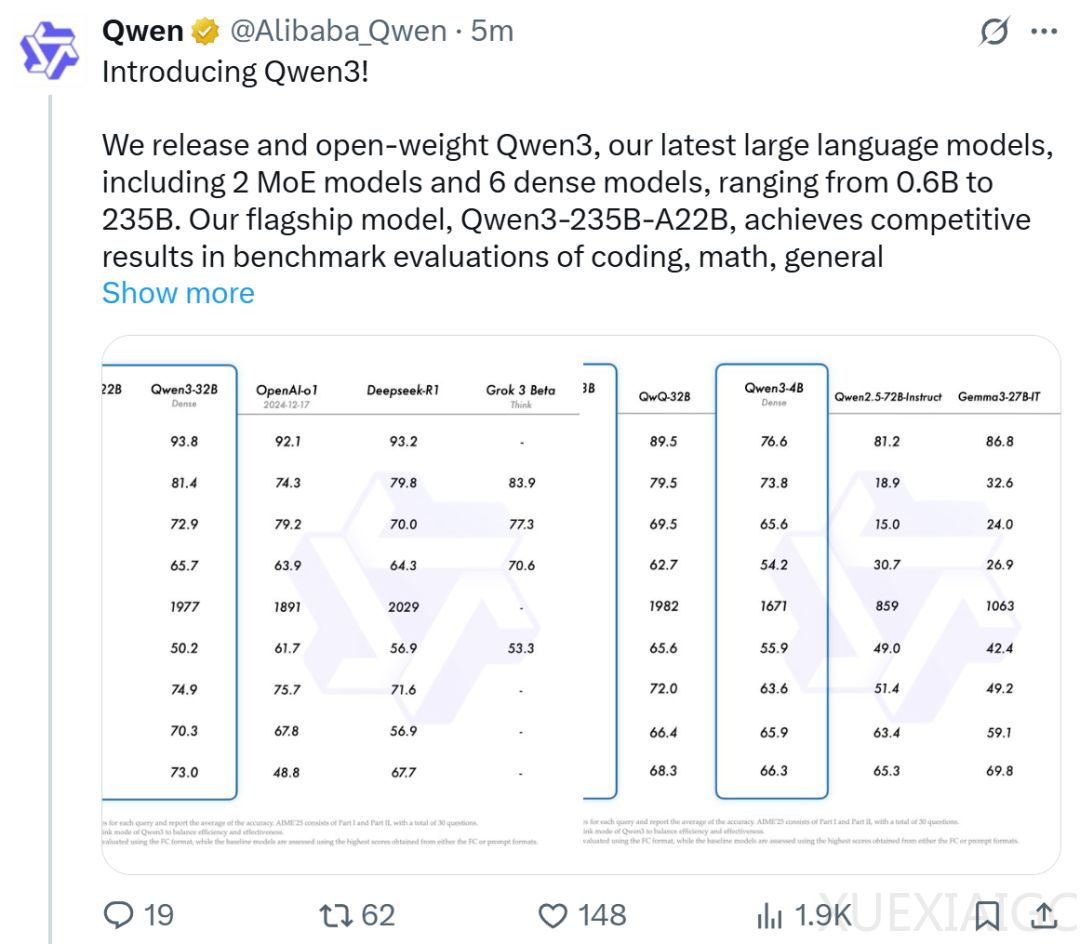
Qwen3系列模型正式发布,采用Apache2.0协议开源,全球开发者、研究机构和企业均可免费下载并商用。该系列包含两款MoE模型和六款密集模型,每款模型又分为基础版和量化版等多个版本。旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中表现优异,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相当。小型MoE模型Qwen3-30B-A3B的激活参数数量仅为QwQ-32B的10%,但性能更优。Qwen3系列模型的部署成本大幅下降,仅需4张H20即可部署满血版,显存占用仅为性能相近模型的三分之一。
Qwen3系列模型在性能提升的同时,部署成本显著降低,显存占用仅为性能相近模型的三分之一。开发团队推荐使用SGLang和vLLM等框架进行部署,本地使用则推荐Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具。这些工具确保用户可以轻松将Qwen3集成到工作流程中,无论是用于研究、开发还是生产环境。
Qwen3系列模型支持两种思考模式:思考模式和非思考模式。思考模式适用于需要深入思考的复杂问题,非思考模式则适用于对速度要求高于深度的简单问题。这种灵活性使用户能够根据具体任务控制模型进行「思考」的程度,大大增强了模型实现稳定且高效的「思考预算」控制能力。Qwen3展现出的可扩展且平滑的性能提升,与分配的计算推理预算直接相关。
Qwen3系列模型支持119种语言和方言,增强了多语言能力,为国际应用开辟了新的可能性。此外,Qwen3模型的Agent和代码能力得到增强,包括加强了对MCP的支持。这些增强使得Qwen3在处理复杂任务时表现出色,尤其是在数学、代码和推理等领域。
在预训练方面,Qwen3的数据集相比Qwen2.5有了显著扩展,达到了约36万亿个token,涵盖了119种语言和方言。开发团队从网络上收集数据,并从PDF文档中提取信息,利用Qwen2.5-VL和Qwen2.5改进提取内容的质量。此外,开发团队利用Qwen2.5-Math和Qwen2.5-Coder合成数据,增加了数学和代码数据的数量。
Qwen3系列模型在预训练和后训练阶段均进行了优化,确保了模型在多种任务和领域中的优异表现。预训练过程分为三个阶段,分别提供了基本的语言技能和通用知识、增加了知识密集型数据的比例,并扩展了上下文长度。后训练阶段则通过四阶段的训练流程,进一步增强了模型的推理和快速响应能力。
Qwen3的发布是阿里通义千问的又一里程碑,Qwen系列已成为全球第一的开源模型。阿里通义已开源了200余个模型,全球下载量超3亿次,Qwen衍生模型数超10万个,已超越Llama,成为全球最大的开源模型族群。在全球AI技术竞争日益激烈的背景下,阿里通义千问通过持续的技术创新和开放合作,推动了AI技术的普及与发展,展现了中国科技企业在全球开源AI生态中的强大影响力。
原文和模型
【原文链接】 阅读原文 [ 2828字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



