文章摘要
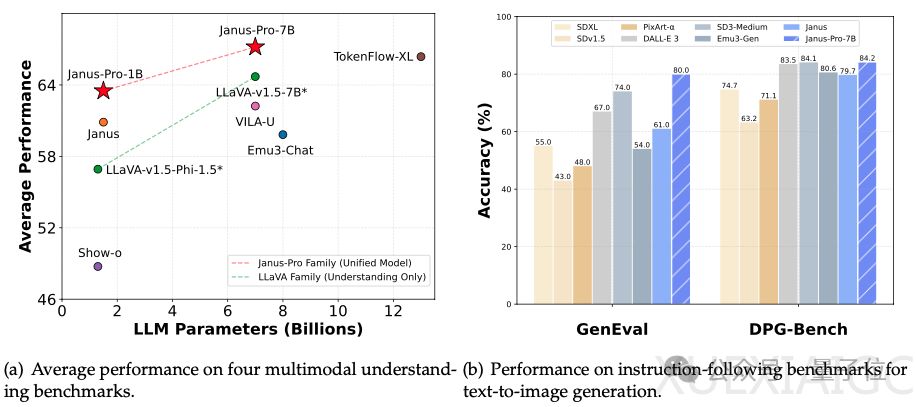
DeepSeek最近发布了新模型多模态Janus-Pro-7B,并立即开源。这一新模型在GenEval和DPG-Bench基准测试中超越了DALL-E 3和Stable Diffusion。Janus-Pro-7B基于DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base构建,采用自回归框架,通过解耦视觉编码来增强模型的灵活性和性能。在多模态理解方面,使用SigLIP-L作为视觉编码器,而在图像生成方面,使用LIamaGen中的VQ标记器。团队对训练策略进行了调整,增加了第一阶段的训练步骤,并在第二阶段放弃了ImageNet数据,直接利用文本到图像数据训练模型。这些改进使得Janus-Pro-7B在视觉生成和多模态理解性能上与现有SOTA模型持平。
DeepSeek的火爆程度不仅在科技圈引起轰动,甚至非科技圈人士也在讨论。例如,游戏科学创始人、《黑神话:悟空》制作人在微博上表示支持,而流浪地球导演郭帆也注意到了DeepSeek。DeepSeek的开源推理模型R1以其低成本和高性能征服了全球用户,引发了行业地震。R1的训练成本仅为560万美元,相当于Meta GenAI团队任一高管的薪资,却在多个AI基准测试中达到甚至超越了OpenAI o1模型。
DeepSeek的成功引发了关于AI算力投资必要性的讨论。英伟达股价暴跌17%,市值蒸发近6000亿美元,而博通、AMD等芯片巨头也大幅下跌。英伟达回应称,DeepSeek展示了如何利用广泛可用的模型和符合出口管制规定的算力创建新模型。Meta和OpenAI也受到了影响,Meta成立了研究小组分析DeepSeek技术,而OpenAI则计划发布新模型o3-mini。
与此同时,阿里旗下的大模型通义千问Qwen也更新了开源家族,发布了视觉语言模型Qwen2.5-VL,包括3B、7B和72B三种尺寸,支持视觉理解、Agent、长视频理解和事件捕捉等功能。
原文和模型
【原文链接】 阅读原文 [ 2034字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




