清华、哈工大把大模型压缩到了1bit,把大模型放在手机里跑的愿望就快要实现了!
模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 模型压缩、1bit量化、性能保持、计算效率、知识迁移
摘要总结:
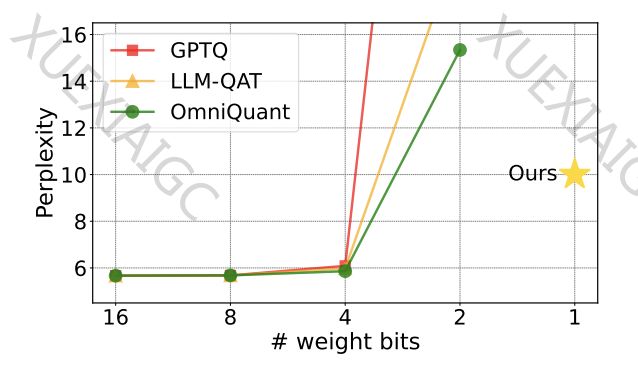
清华大学和哈尔滨工业大学的研究团队在模型量化领域取得了重要进展,他们提出了一种名为「OneBit」的方法,成功将大型语言模型(LLM)压缩至1bit,同时保持了约83%的性能。这一成果不仅突破了2bit量化的障碍,还为在PC和智能手机上部署大模型提供了可能。
已有工作的局限性:
以往的模型量化方法主要依赖于Round-To-Nearest(RTN)方法,但在3bit以下的量化中存在严重精度损失。此外,1bit量化的研究尚未取得实质性进展,如BitNet方法虽然实现了1bit表示,但性能损失严重,训练不稳定。
OneBit框架:
OneBit框架包括三个核心部分:新的1bit层结构、基于SVID的参数初始化方法和基于量化感知知识蒸馏的知识迁移。这一框架通过引入FP16格式的值向量来补偿量化导致的精度损失,同时保持了参数矩阵的高秩。
实验及结果:
OneBit在不同规模的模型上进行了测试,包括1.3B到13B的OPT和LLaMA系列模型。在验证集的困惑度和Zero-shot准确度上,OneBit表现出色,尤其是在模型规模增大时,其性能增益更为显著。此外,OneBit在计算上的优势也得到了体现,纯二进制参数使得矩阵乘法可以高效完成。
讨论与分析:
OneBit在压缩比上达到了90%以上,且随着模型规模的增大,压缩比越高。尽管1bit量化可能导致性能损失,但OneBit在大小和性能之间取得了良好的平衡。研究团队还提出了未来可能的研究方向,包括寻找更优的参数初始化方法和考虑激活值的量化。
结论:
OneBit方法为大模型的压缩和部署提供了新的解决方案,其在保持性能的同时实现了空前的压缩幅度,对于推动AI模型在各种设备上的广泛应用具有重要意义。
原文信息
【原文链接】 阅读原文
【阅读预估】 2962 / 12分钟
【原文作者】 机器之心
【作者简介】 专业的人工智能媒体和产业服务平台

相关文章



