没等来OpenAI,等来了Open-Sora全面开源
模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★★☆☆
文章摘要
【关 键 词】 Sora视频生成、Diffusion Transformer、STDiT模型、多阶段训练、Colossal-AI加速
机器之心编辑部近期报道了OpenAI Sora视频生成模型的开源进展。Sora因其出色的视频生成效果而受到全球关注。在成本降低46%的Sora训练推理复现流程发布两周后,Colossal-AI团队推出了全球首个类似Sora架构的视频生成模型Open-Sora 1.0,并全面开源了整个训练流程,包括数据处理、训练细节和模型权重。这一举措旨在与全球AI爱好者共同推进视频创作的新时代。
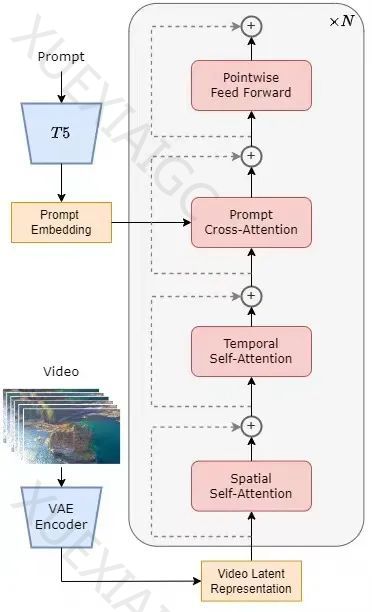
Open-Sora 1.0的模型架构基于当前流行的Diffusion Transformer (DiT)架构,采用预训练的VAE、文本编码器和空间-时间注意力机制的STDiT (Spatial Temporal Diffusion Transformer)模型。STDiT模型通过串行方式叠加空间注意力模块和时间注意力模块,有效降低了训练和推理开销。模型的训练和推理流程包括使用VAE编码器压缩视频数据,与文本嵌入一起训练STDiT扩散模型,以及在推理阶段从VAE潜在空间中采样高斯噪声,输入到STDiT中得到去噪特征,最后解码得到视频。
Open-Sora的复现方案参考了Stable Video Diffusion (SVD)工作,分为三个阶段:大规模图像预训练、大规模视频预训练和高质量视频数据微调。这一多阶段训练方法通过逐步扩展数据集,更高效地实现高质量视频生成。数据预处理方面,Colossal-AI团队提供了便捷的视频数据预处理脚本,降低了Sora复现的技术门槛。
Open-Sora的实际视频生成效果展示了其在生成各种场景的能力,如悬崖海岸、山川瀑布、水中世界和银河等。尽管目前版本仅使用了400K的训练数据,模型的生成质量和文本遵循能力仍有提升空间,作者团队已在GitHub上列出了一系列待解决的问题和优化计划。
此外,Colossal-AI加速系统为Sora复现提供了高效训练支持,通过算子优化和混合并行策略实现了1.55倍的加速效果。STDiT模型架构在训练时也展现出高效性,与全注意力机制的DiT相比,实现了高达5倍的加速效果。
作者团队表示将继续维护和优化Open-Sora项目,计划使用更多视频训练数据,以生成更高质量、更长时长的视频内容,并支持多分辨率特性,推动AI技术在电影、游戏、广告等领域的应用。感兴趣的朋友可以访问Open-Sora的开源社区获取模型权重进行体验。
原文信息
【原文链接】 阅读原文
【阅读预估】 2569 / 11分钟
【原文作者】 机器之心
【作者简介】 专业的人工智能媒体和产业服务平台

相关文章





